With a great amount of available data to analyze on the web, it is essential to associate it with web scraping technology, which is able to effectively reduce manual work and the operation cost in the first stage of the big data solution.
When talking about web scraping technology, Google spider could be the first thing that appears in our mind. However, it could be widely used in various scenarios. Before further discussion on the use cases here, this article will help you understand the working logic of the web scraping technology and how to quickly master web scraping skills.
How does a web scraper work?
All web scrapers work in the same manner. They first send a “GET” request to the target website, and then parse the HTML accordingly. However, there are some differences between using computer languages and web scraping tools.
The following code snappit shows an example of a web scraper using Python. You will find yourself inspecting the web structures most of the time during the scraping.
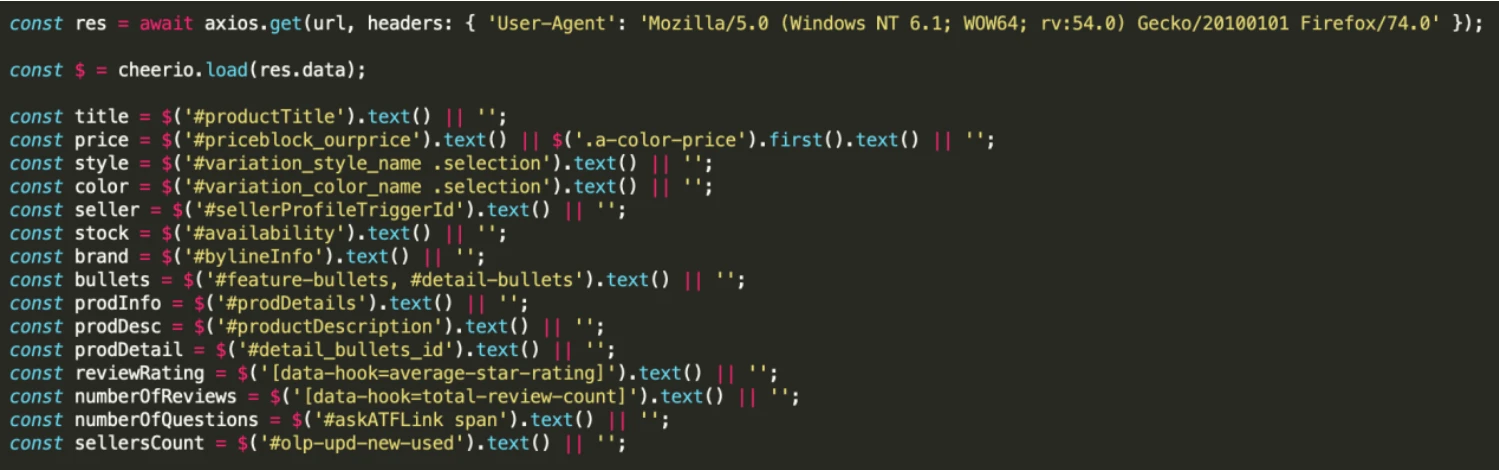
- Line 1 is the GET part. It sends a “GET” query to the website and then returns all the text information.
- Line 2 is to LOAD the text we request and present it in HTML format.
- Starting from Line 3 till the end, we begin to PARSE the HTML structure and obtain the data/information we need.
If you think it looks like an alien’s workbook which doesn’t make any sense to a human being, I’m with you. The process of getting the web data shouldn’t be more complex than copying-and-pasting. This is where the magic of a web scraping tool comes into place.
If you have downloaded Octoparse and used it for a while, you should have tried Octoparse Task Template Mode and Advanced Mode. When you enter a target URL in Octoparse, Octoparse helps you to read it, which is regarded as sending a “GET” query of the target website.
No matter which mode you use to build a web scraper, the essential action is to parse the target website. A task template is a ready-to-use parser that is pre-built by the Octoparse crawler team while a customized task requires users to click to create a parser.
How to create a scraper from scratch?
We have learned the basic working logic of the scraper in the previous part, now we can start practicing how to create a scraper from scratch. In this part, you’re going to learn 2 methods:
Method 1: Build a scraper with Octoparse 8.1
- Auto-generated scraper: enter the target URL to get data
Method 2: Build a scraper with Python
- Step 1: Inspect your data source
- Step 2: Code the GET Part in Pycharm
- Step 3: Code the PARSE Part in Pycharm
Task description: to make the practice more newbie-friendly,
Target website: https://www.imdb.com/india/top-rated-indian-movies/
In this case, our task is to scrape the list of the
Build a scraper with Octoparse 8.1
- Auto-generated scraper: enter the target URL to get data
Build a scraper with Python
- Step 1: Inspect your data source
Simply click “F12” to open the Chrome code developer to inspect the HTML. We Can figure out the request URL which contains the data we need. Here, we can see that the URL we selected contains all the data we want.
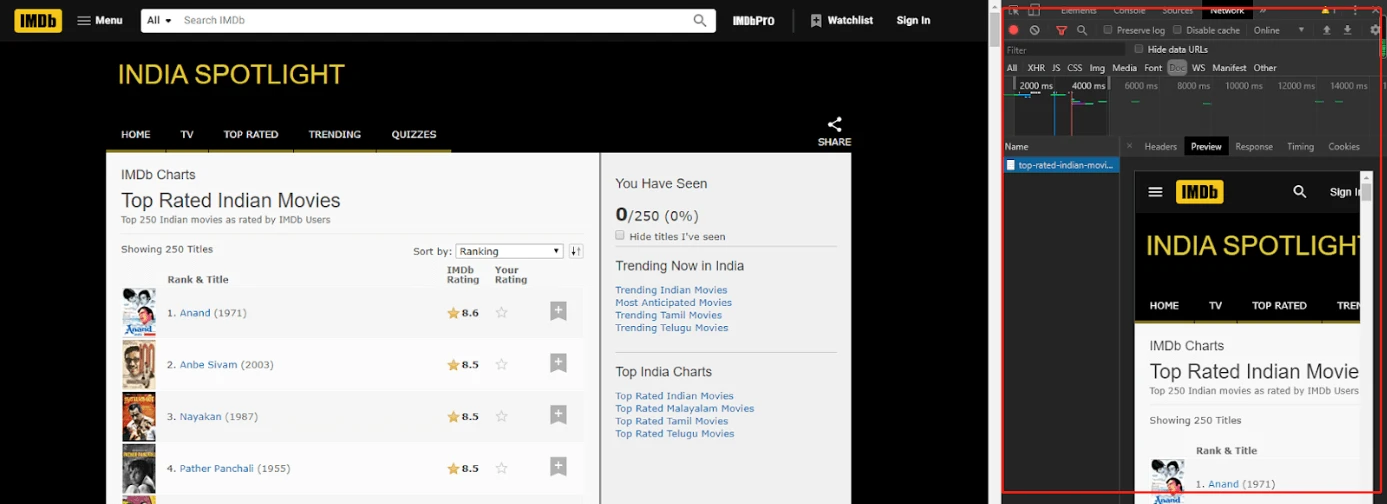
- Step 2: Code the GET Part in Pycharm
Before coding the spider part, we need to import “some resources” which is a Python library as follows. So does the target URL, https://www.imdb.com/india/top-rated-indian-movies/
This function is made to get the data from IMDB’s top Indian movies link also it program converts into JSON format it basically it program gives us position, movie URL, movie name, movie year, and rating.
- Step 3: Code the PARSE Part in Pycharm
There are two ways to achieve the PARSE Part: Using Regex OR a Parse tool, like Beautiful Soup. In this case, to make the whole process easier, we use Beautiful Soup. After installing the Beautiful Soup into your computer, simply add the two lines which are highlighted in yellow to your Python file.
With the above steps, the IMDB task is done! All you need to do is to run the code and store the data to your computer.
Final thoughts
All in all, creating a crawler and conducting data scraping is not the exclusive field for the programmers anymore. More and more people who have barely coding background can scrape the online data with the assistance of some cutting-edge tools, like Octoparse.
Now, it’s easier for us to step into the big data area with the assistance of tools than before. Maybe, at this time, what we need to further consider is what value we can get from the data and information we get online.




