Data mining is to extract valid information from gigantic data sets and transform the information into potentially useful and ultimately understandable patterns for further usage. Not only does it include data processing and management, but it also involves the intelligence methods of machine learning, statistics and database systems, as Wikipedia defines.
To help our audience master the technology of data science, we published 80 Best Data Science Books That Worth Reading and 88 Resources & Tools to Become a Data Scientist. In this article, we will focus on the 10 essential data mining skills from 4 main aspects.
At the very beginning, if you are still confused about the data mining concept, here is a video explaining the differences between data mining and data extraction.
Computer Science Skills for Data Mining
1. Programming/statistics language:
R, Python, C++, Java, Matlab, SQL, SAS, shell/awk/sed…
Data mining relies heavily on programming, and yet there’s no conclusion on which is the best language for data mining. It all depends on the dataset you deal with. Peter Gleeson put forward four spectra for your reference: Specificity, Generality, Productivity, and Performance. They can be viewed as a pair of axes (Specificity- Generality, Performance – Productivity). Most languages can fall somewhere on the map. R and Python are the most popular programming languages for data science, according to research from KD Nuggets.
|
More resources: Which Languages Should You Learn for Data Science [Freecode Camp] Data Mining Algorithms In R [Wikibooks] Best Python Modules for Data Mining [KD Nuggets] |
2. Big data processing frameworks:
Hadoop, Storm, Samza, Spark, Flink
Processing frameworks compute over the data in the system, like reading from non-volatile storage and ingesting data into your data system. This is the process of extracting information and insights from large quantities of individual data points. It can be sorted out into 3 classifications: batch-only, stream-only, and hybrid.
Hadoop and Spark are the most implemented frameworks so far since Hadoop is a good option for batch workloads that are not time-sensitive, and is less expensive to implement than others. Whereas, Spark is a good option for mixed workloads, providing higher speed batch processing and micro-batch processing for streams.
|
More resources: Hadoop, Storm, Samza, Spark, and Flink: Big Data Frameworks Compared [Digital Ocean] Data Processing Framework for Data Mining [Google Scholar] |
3. Operating System:
Linux
Linux is a popular operating system for data mining scientists, which is much more stable and efficient o/s for operating large data sets. It is a plus if you know about common commands of Linux, and are able to deploy a Spark distributed machine learning system on Linux.
4. Database knowledge:
Relational Databases & Non-Relational Databases
To manage and process large data sets, you must have knowledge of relational databases, like SQL or Oracle. Or you need to know non-relational databases, whose main types are: Column: Cassandra, HBase; Document: MongoDB, CouchDB; Key value: Redis, Dynamo.
Statistics & Algorithm Skills for Data Mining
5. Basic Statistics Knowledge:
Probability, Probability Distribution, Correlation, Regression, Linear Algebra, Stochastic Process…
Just recalling the definition of data mining at the beginning, we know that data mining isn’t all about coding or computer science. It sits at the interfaces between multiple fields, among which statistics is an integral part. Basic knowledge of statistics is vital for a data miner, which helps you to identify questions, obtain a more accurate conclusion, distinguish between causation and correlation, and quantify the certainty of your findings as well.
|
More resources: What Statistics Should I Know to do Data Science [Quora] Statistical Methods for Data Mining [Research Gate] |
6. Data Structure & Algorithms
Data structures include arrays, linked list, stacks, queues, trees, hash table, set…etc, and common Algorithms include sorting, searching, dynamic programming, recursion…etc
Proficiency in data structures and algorithms is critically useful for data mining, which enables you to come up with more creative and efficient algorithmic solutions when processing large volumes of data.
|
More resources: Data, Structure, and the Data Science Pipeline [IBM Developer] Coursera: Data Structures and Algorithms [UNIVERSITY OF CALIFORNIA SAN DIEGO] |
7. Machine Learning/Deep Learning Algorithm
This is one of the most important parts of data mining. Machine learning algorithms build a mathematical model of sample data to make predictions or decisions without being explicitly programmed to perform the task. And deep learning is part of a broader family of machine learning methods. Machine learning and data mining often employ the same methods and overlap significantly.
|
More resources: Essentials of Machine Learning Algorithms with Python and R Codes [Analytics Vidhya] A Curated List of Awesome Machine Learning Frameworks, Libraries, and Software (by language) [Github josephmisiti] |
8. Natural Language Processing
Natural Language Processing (NLP), as a subfield of computer science and artificial intelligence, helps computers understand, interpret and manipulate human language. NLP is widely used for word segmentation, syntax and semantic analysis, automatic summarization, and textual entailment. For data miners who need to deal with a large amount of text, it is a must-have skill to get to know the NLP algorithms.
|
More resources: 10 NLP Tasks for Data Scientists [Analytics Vidhya] A Curated List of Awesome Machine Learning Frameworks, Libraries, and Software (by language) [Github josephmisiti] Open Source NLP Libraries: Standford NLP; Apache OpenNLP; Naturel Language Toolkit |
Easy Data Mining Tools
9. No-Coding Data Scraping Tool
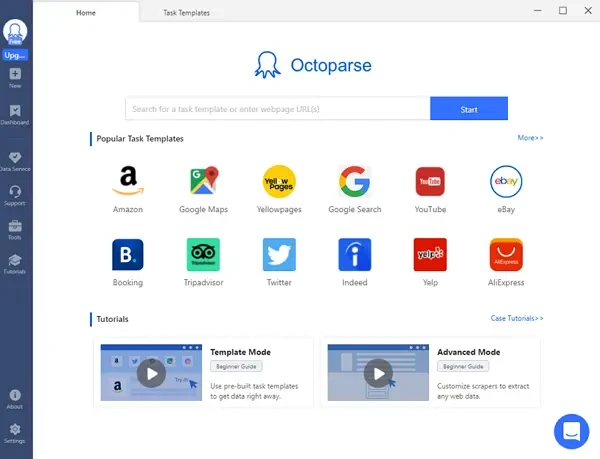
Using tools to help your data mining processing is important. As a simple but powerful web data mining tool, Octoparse is a great choice for you that it automates web data extraction. It allows you to create highly accurate extraction rules. Crawlers run in Octoparse are determined by the configured rule. The extraction rule would tell Octoparse which website to go to, where the data is you plan to crawl, what kind of data you want, and much more.
You can extract data by using Octoparse web data miner within 3 easy steps. Or you can follow Octoparse detailed user guide.
Step 1: Copy and paste the target URL to Octoparse main panel after you have downloaded it on your devices.
Step 2: Extract data by the auto-detect mode and customize the workflow on the right panel. Or you can try the pre-set templates.
Step 3: Run the task after you have a preview. After a few minutes, you can download the data to Excel, CSV or other formats that are able for further use.
Social Skills
10. Communication & Presentation Skills
Data miners do not only deal with data but also are responsible to explain the outcomes and insights drawn from data to others. Sometimes they need to explain them to non-technical audiences, such as the marketing team. You should be able to interpret data outcomes and tell the stories, in oral, written and presentation means well.