Extracting text from an HTML file is literally the same thing as copying-and-pasting webpage information onto a notepad. It may sound simple, but imagine if you were to extract text from thousands of HTML files (webpages), it wouldn’t be as fun then. As a matter of fact, extracting text from web pages serves a lot of practical uses, just to name a few:
- Download the blogs from webpages
- Download all news articles from a specific website
- Capture product information such as the SKU, model, and description from eCommerce websites like Amazon and eBay.
- Extract only the text part of the web page, without the tables, images, or other forms of data
- Clean a messy HTML file to include only the readable content from the file
How Text is Embedded into an HTML File
For whatever reason you need to extract text from an HTML file, it helps to learn a bit about how texts or different types of data are embedded in an HTML file before getting to work.
The main component of an HTML file is an array of elements within which all types of data are embedded, including text. These elements are arranged in a certain way to form the layout of a web page.
This is an example taken from one of the W3School HTML exercises:
<p>
This paragraph
contains a lot of lines
in the source code,
but the browser
ignores it.
</p>
You can view the above as an element. <p> and </p> as the tags (the former marks an opening and the latter an end). Text is often wrapped between tags such as <p>, <span>, <h>, etc.
Understanding the structure of an HTML file would be helpful if you only wish to extract a particular piece of data from the HTML file (or the webpage). And this is exactly how Xpath would come into play – a query language for selecting elements from an XML/HTML document.
How to Extract Texts from HTML
There are two things you can try for capturing text from HTML files.
Programming Language
For those simple HTML documents, people who have basic coding knowledge would choose to write a program to remove all HTML tags and retain only the text inside HTML files, using Regular Expression or XPath. There are several widely used programming languages such as C#, Java, Python, JS, PHP, Go, and NodeJs that are available for computer programmers.
Some of these languages have their own parser for HTML that are available for free and you will know more about these HTML parsers by clicking here https://en.wikipedia.org/wiki/Comparison_of_HTML_parsers.
Testing and debugging your codes can take up some time which should be well expected if you’ve had any experience with coding at all.
Web Data Extraction Tools
There are many powerful web extraction tools, such as Octoparse, available for you to harvest almost everything on the web page, including the text, links, images, etc. You can convert whatever you get into a structured data format.
There’s no need for any coding, so it’s good for those who have no coding experience. In most cases, you don’t need to write Regular Expression or XPath, but it’s always going to be a plus if you want to fulfill more sophisticated data requirements. Octoparse, as it is designed for non-coders, comes with a user-friendly interface that allows you to easily interact with the web pages. It’s easy to manage and export the data without an IDE.
If you are a non-coder, Octoparse’s Auto-detect mode would be extremely helpful for you to get started. The software will detect the web page automatically and have the valuable data organized in a spreadsheet for you.
Here are some hands-on guides you may be interested in:
Scraping Movies from IMDb, Flixster, etc.
HTML Extraction Example
If you are still a newbie to any programming language but want to download information from web pages eagerly, a web scraping tool can be extremely helpful. Octoparse’s auto-detect algorithm makes data scraping easy for no-coders. For most of the webpage out there, you can get it done in only three simple steps.
- Enter the target URL
- Launch auto-detection
- Run the task for data scraping
I am taking this page as an example: https://techcrunch.com/
Say you want to scrape the blogs from Techcrunch (or any other similar websites), simply enter the URL into Octoparse and launch the auto-detection, you will get a scraper that helps get you the structured data as below:
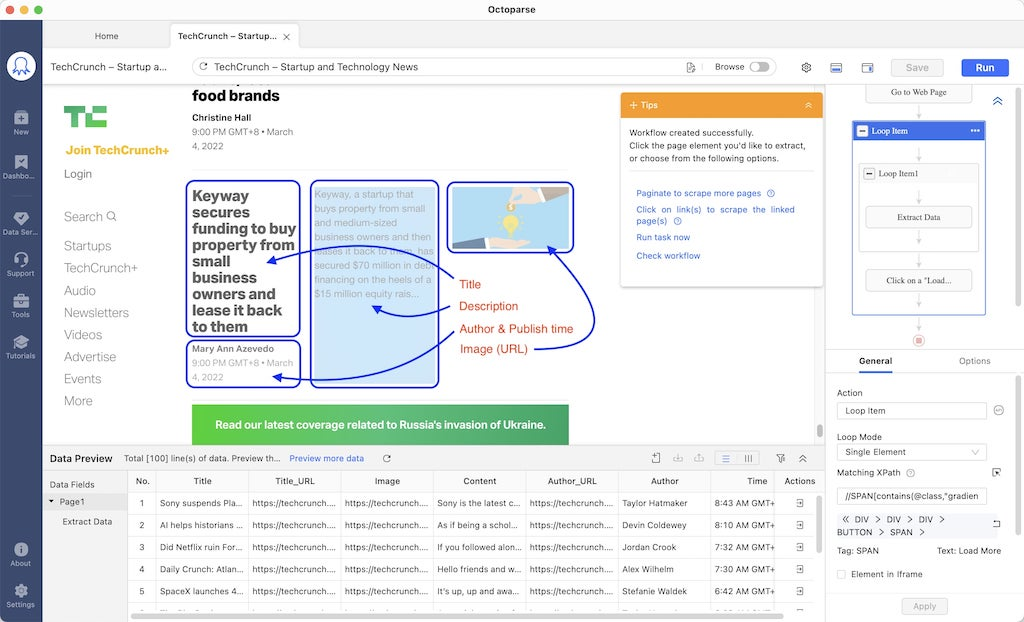
By clicking the “save” button, you’ve got yourself a scraper at your disposal. You can run the scraper any time you need the data or put it on schedule for regular data feeds.
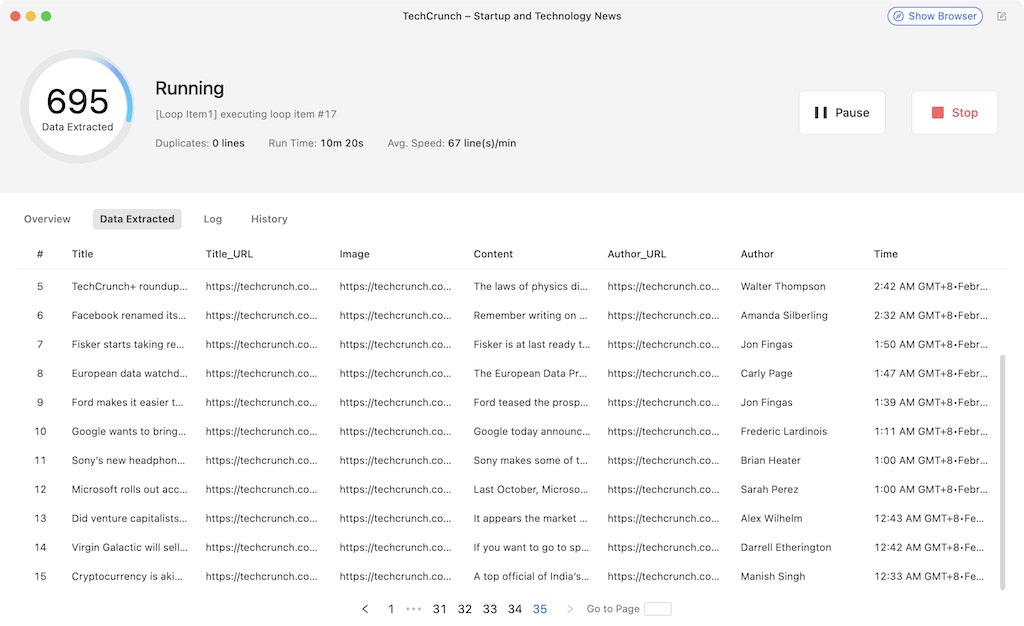
If you opt for local runs, you’ll actually get to see the process working in real-time. When the task is completed, you can download the data in Excel, CSV, or JSON. With the help of Octoparse, data extraction from an HTML file can be this easy.
Download Octoparse now and try it out yourself.




