Staying informed is essential in the quickly changing modern world, and CNN has long been a dependable source of up-to-date news. But because so much data is produced every day, it might be difficult to locate precise information. This info-tidal wave can be navigated with the aid of web scraping, a method for gathering vast amounts of data from websites to be stored on your computer or database. It makes it possible to quickly and extensively extract data from CNN, which facilitates effective analysis and decision-making. This article demystifies web scraping by outlining its goal and offering guidance on how to use it without any prior coding skills.
About CNN News
CNN News is a well-known worldwide news outlet and digital media platform that offers in-depth reporting on a variety of subjects, such as business, politics, science, and technology. The website features feature stories, opinion pieces, and the most recent news from informed writers. Users may easily locate news that is trending locally and globally thanks to the user interface’s categorization and convenience of use. In addition to engaging multimedia material, the website features podcasts, movies, and images.
Web Scraping on CNN News
CNN Web Scraping is the process of obtaining valuable data from CNN’s online platform using web scraping technologies. As one of the biggest news outlets, CNN provides a wealth of information through articles, blogs, and multimedia content. The huge volume of information available here can be mined for data using web scraping or data extraction tools.
These programs can be designed with the express purpose of navigating the CNN website, extracting particular information from articles—like article names, authors, publishing dates, and content—and storing that information in an Excel or CSV file. Researchers, analysts, and companies looking to gather and examine news patterns, journalistic bias, or any other specific type of data dispersed throughout CNN’s extensive web content library may find it very helpful. Manually carrying out this kind of work would take a lot of time and be unfeasible. Please be aware that in order to prevent any legal issues, web scraping must be carried out in accordance with CNN’s terms of service or with their express consent.
Why do People Scrape CNN?
Data Collection for Content Aggregation: Data Gathering via Scraping for Content Aggregation CNN gives companies, academics, journalists, and people access to a wealth of knowledge that they may use for a range of tasks, such building news aggregator websites, doing market research, or doing data analysis for scholarly or journalistic purposes.
Useful for AI and Machine Learning: CNN content is helpful for training artificial intelligence (AI) and machine learning. These scraped stories can be used by researchers in fields like sentiment analysis and natural language processing to train their algorithms to identify different sentiments or understand different linguistic patterns in news reporting.
Analyzing Public Sentiments: Tracking the recurrence of particular words or topics over time gives insight into their significance in public discourse. The news articles’ comment sections are also excellent tools for gauging public sentiment on a range of topics.
Step-by-step Guide to Scrape CNN News Without Coding
Web scraping tools like Octoparse are immensely useful in today’s data-driven world, especially for non-technical users. It is a highly robust and powerful news and article scraper that permits users to extract and transform content from news websites into structured data without coding. This is good for news scraping needs. Just by clicking and selecting on the website’s items, even non-programmers can scrape the news and article data easily.
Octoparse extracts data that may be stored in a variety of databases and formats, simplifying analysis and insight findings. It is a useful tool for navigating the big data era, regardless of the user’s purpose: market researcher looking for information for business analysis, journalist needing quick access to data, or academic researcher needing large data sets.
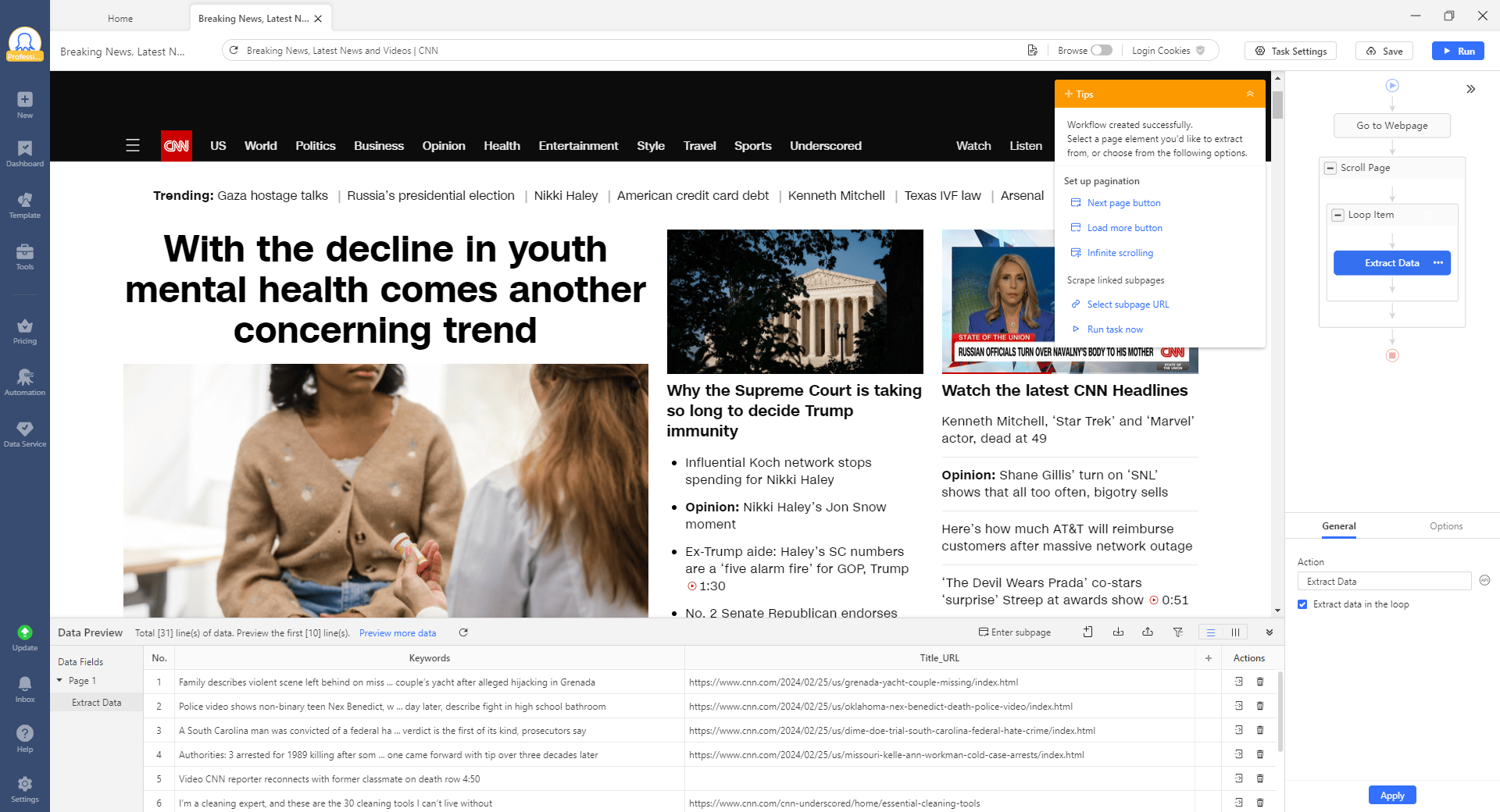
Step 1: Create a CNN scraping task
Enter the CNN URL into the search bar, then click the Start button. The page will be loaded in the Octoparse built-in browser.
Step 2: Select CNN data
Once the CNN web page has fully loaded, click the “Auto-detect website data” button, which prompts Octoparse to analyze the page and identify any extractable data elements. Then review the potential data sets identified by clicking “switch auto-detect results”. All detected data fields will be visually highlighted on the page and previewed in the section below.
Click “Create workflow” to generate a workflow on the right. The chart shows each step; click steps to check performance individually and verify each captures the right data before running the full extraction. You have the option to remove unnecessary columns or modify column names to tailor the extracted data according to your specific requirements.
Step 3: Scrape and export CNN data
Once you have checked all the news data, click the run button to start the scraping process. You can choose to run your scraping task in the cloud or on your local device if you don’t have one. Finally download the collected news and article data in Excel, CVS, or any other format that is good for further uses.
Wrap up
Web scraping has become a vital method for rapidly and effectively obtaining large volumes of data, especially in media sources like CNN. The major reason people scrape CNN is because of its current coverage, which offers a wide range of global insights. It is a trustworthy resource for researchers, journalists, and data analysts. The utilization of tools such as Octoparse, with its intuitive interface has made this procedure more convenient. Therefore, web scraping can be a useful technique for obtaining a variety of information from reputable news websites like CNN in an easy-to-manage manner as long as it is done ethically.




