In short, web scraping is a way to download data from web pages. It is the automated process of extracting data from websites and converting it into structured, usable formats like spreadsheets, databases, or APIs.
The global web scraping software market was valued at over $718 million in 2024 and is expected to reach approximately $2.2 billion by 2033, which shows how critical automated data collection has become for modern businesses.
Over 65% of organizations now use web scraping to build AI models and gather domain-specific datasets, while retailers increasingly rely on it for real-time price monitoring and competitive intelligence.
Understanding Web Scraping Terminology
You may have heard some of its nicknames like data scraping, data extraction, or web crawling. Among these, web crawling could be narrower and refer to data scraping done by search engine bots. But in most cases, they all refer to the same meaning – a programmatic way to pull data from the web.
At its essence, web scraping captures specific data you need from websites and organizes it into formats you can actually use: Excel files, CSV exports, JSON for APIs, or direct database imports like Google Sheets or SQL databases.
Common data types include:
- Product information (prices, descriptions, specifications, availability)
- Contact details (email addresses, phone numbers, business listings)
- Content and articles (news, reviews, social media posts)
- Financial data (stock prices, market trends, real estate listings)
- Research datasets (academic papers, public records, sentiment analysis sources)

Read the article in infographics
What is the Point of Web Scraping
If I had to explain the point of web scraping in one sentence: “It’s the fastest way to get the data you need without wasting human hours on repetitive work.”
The real reason people scrape: time and scale.
Big data is big for the amount. Automation is about getting things done on autopilot. Web scraping is good at both – getting voluminous data fast with little human labor required.
When you strip away the tech jargon, it comes down to three truths:
- You need a lot of data
- You need it fast
- You definitely don’t want to copy and paste it yourself
Scraping does all of that.
Whether you’re building a lead list, tracking competitors, monitoring prices, or feeding an AI model, it lets you collect thousands — even millions — of data points without losing your weekend (or your patience).
Why It Matter Today?
In the world of big data and AI, scraping has gone from “nice to have” to “completely essential.”
If you’re training a machine learning model, the quality and size of your dataset basically determine how smart your model becomes. More accurate data → better results. It’s that simple.
And this is where scraping plays its ace:
It grabs fresh, relevant data from multiple sources and puts it directly into a clean, machine-readable format.
The AI and Machine Learning Revolution
Over 65% of organizations now use web scraping to gather domain-specific datasets for AI model training.
Think about how today’s big AI models are built — ChatGPT, Claude, Gemini. They all rely on enormous datasets like Common Crawl and LAION-5B. Those datasets exist because automated scrapers scan billions of pages across the internet.
Without scraping, modern AI wouldn’t exist.
Period.
For data scientists and ML engineers, scraping gives them what traditional datasets can’t:
- Fresh, real-time data
Models stay up-to-date instead of relying on stale snapshots - Domain-specific datasets
You can scrape exactly the niche data you need—like medical papers, product reviews, or financial filings - Data augmentation at scale
When your dataset is too small, scraping lets you pull more examples to make your model stronger, more accurate, and less biased
How Does Web Scraping Work
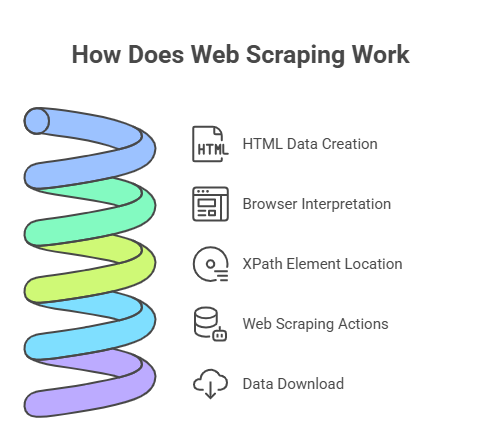
Websites’ data is written in HTML files. Browsers like Chrome and Firefox are tools that read the HTML file to us.
Therefore, no matter how diverse web pages are presented to us, every string of data we see in the browser is already written in the HTML source code. With XPath, a language that locates elements on the page, you can trace what you see in the code.
Web scraping finds the right data according to where it locates and takes a series of actions, such as extracting the selected text, extracting the hyperlink, inputting preset data, clicking certain buttons, etc., just like a human, except that it surfs the Internet and copies the data fast around the clock and feels no fatigue.
Once the data is ready, you will be able to download it from the cloud or to the local file for any further use.
How is Web Scraping Used
Who uses web scraping and how does it empower them? Read the use cases below, and then you may discover how web scraping could benefit you as well.
Who is using web scraping
Almost everyone needs reliable data:
- Many industries can benefit from web scraping including:
- jobs & recruitment
- consultancy
- hotel & travel
- eCommerce & retailing
- finance and more
- marketing
They get data mostly for price monitoring, price comparison, competitor analysis, big data analysis, etc., that serve their decision-making process and business strategies.
For individuals, web scraping helps professionals like:
- data scientists
- data journalists
- marketers
- academic researchers
- business analysts
- eCommerce sellers and more
They all hate repetitive work. Web scraping solves that — it boosts productivity, cuts human errors, and handles all the grunt work so your team doesn’t have to.

Does web scraping sound like a big undertaking to you?
Believe me, it is not.
It can be used in many trivial ways and help you out of tedious, repetitive work. Basically, if you need data that could be found on websites and you don’t want to do mind-numbing copies and pastes manually, you use web scraping.
Read also:
- How Dealogic Gets Empowered with Content Aggregation
- E-commerce Product Tracking for Successful Reselling
- Web Scraping In Marketing Consultancy
- Web Scraping Manages Inventory Tracking in Retail Industry
What are the most scraped data and websites
According to the post Most Scraped Websites, e-commerce marketplaces, directory websites, and social media platforms are the more scraped websites in general. Websites like Amazon, eBay, Walmart, Yellow Pages, Craigslist, and social media platforms like Twitter and LinkedIn are among the popular.
What data are people getting from these sites? Well, everything that serves their research or sales.
- Online product details like stock, prices, reviews, and specifications;
- Business/leads information like stores’ or individuals’ names, email addresses, phone numbers, and other information that serve any outbound gestures;
- Discussions on social media or comments on the review pages that offer data sources for NLP or sentiment analysis.
The need to migrate data is also one of the reasons people choose web scraping. A scraper then works out like a grand CTRL+C action and helps copy data from one place to another for the user.
You may be interested in web scraping business ideas to discover more detailed information about how web scraping is used in practical scenarios.
The Pros and Cons of Web Scraping
Because of its accuracy and efficiency, web scraping empowers individuals and businesses in many ways. However, worries always exist – will it be too complicated to handle? Is it hard to fix and maintain? Well, fair questions. If you get the opportunity to dive into it, you will see the advantages of web scraping very likely outweigh what means to you the tricky part.
The advantages of web scraping
High speed
It is self-evident that web scraping can help people get data faster. It may be the core reason people resort to web scraping. Compared to manually doing this, a web scraper can execute your commands automatically, according to the workflow you have built for it. Each step of work that would have taken up your time will be done by the scraper.
The speed advantage is quantifiable: AI-powered scraping delivers 30–40% faster data extraction times, while AI-based scrapers can achieve accuracy rates of up to 99.5% when handling dynamic websites. For businesses dealing with time-sensitive data like price tracking, news aggregation, or stock information, this speed translates directly into competitive advantage.
Once you set it up, it will run for you relentlessly, getting all kinds of web data fast from different websites. If you wanna try how fast a scraper can be, I recommend you try our scraper templates.
You may try an Amazon scraper to gather product details or product reviews and see how a scraper can get you hundreds of well-structured data lines in just a minute.
Thus, web scraping is a valuable tool to study market trends and gaps, the voice of your customers, and the gestures of your competitors since it helps grab this data fast and easily from all different sources.
Download Octoparse to witness the speed of web scraping now.
Cost-effectiveness
Web scraping is widely accepted by not only big companies but also SMBs. It just saves money.
First of all, hiring a development team would cost a lot. Looking for the right talents, dealing with leadership and management stuff to put them together and work effectively, and human resources issues, all of these are time-consuming (and sometimes psyche-consuming).
Web scraping takes repetitive work without the need for a coffee break. Unless you have a long-term development plan to carry out (or you have a big budget to squander), web scraping is worth a try.
The returns of setting up a scraper (or a set of scrapers) can be considerable.
For example, if you want a series of product price information and get it updated daily for a year, you may spend a few days or even weeks configuring the scrapers, testing, and fine-tuning it. Once it is well-built, it can work for you as long as you need it. Fresh price data will be delivered to you every morning, more punctual than the employees in your office.
Well, it is not a once-for-all work. You may spend some time maintaining the scraper# now and then, but it saves you a grand number compared to the cost of data delivery for 365 sets of price data a year.
Related Reading: How Does Web Scraping Cost
Compatibility and flexibility
The flexibility of web scraping enables you to get data exactly in the form you need it. For example, a regular expression is one of the ways to get your data cleaned. You can set commands with regex to refine the strings of data by adding a prefix, replacing A with B, cutting certain bytes of data, etc.
You can use Regex to remove the string “(415)” from every number in your spreadsheet if you are scraping San Francisco local business numbers for your telemarketing system. Data can be cleaned as the scraper processes.
File formats also make things easier. Octoparse scrapes web data into EXCEL, CSV, HTML, and JSON formats. These files are compatible with most apps and systems of data management, data analysis, and visualization.
An Octoparse user once told us that he is running a price comparison website. He set the tasks to run daily so that the prices were fresh. The data scraped is automatically exported to his database which connects to his website.
A web scraper can be a data pipeline that extracts data from the web, cleans it, organizes it into the right format, and copies it to your database which could be then uploaded to your websites and systems. You can’t imagine how an individual could run and maintain a website by himself, getting the data on it refreshed every day without web scraping.
Capacity to get data that API can’t
API is short for Application Programming Interface. An API gives people access to the data of an application or system that is granted by the owner.
Understanding when to use web scraping versus APIs is crucial for effective data collection. APIs provide optimized data delivery with minimal overhead, making them significantly faster for most use cases, but they come with significant limitations.
According to Wikipedia:
“An API is a connection between computers or between computer programs. It is a type of software interface, offering a service to other pieces of software. One purpose of APIs is to hide the internal details of how a system works, exposing only those parts a programmer will find useful and keeping them consistent even if the internal details later change.”
Hence what data you can get through API highly depends on which part of the information is open to the public. In most cases, applications and services would offer only limited access to the public free of charge or sometimes at a cost.
This is where web scraping shines: whereas an API only offers access to specific data, web scraping allows access to any dataset so long as it is accessible to the public. You can tailor your scraper to collect exactly the data you need, not just what a company decides to share through their API. For instance, while Twitter’s API might limit you to recent tweets with specific parameters, a scraper could potentially access historical data, user profiles, and engagement metrics that aren’t available through official channels.
The specification to build an API connection varies from app to app. If you are looking for data from only one or a few sources, and luckily the data you need is all granted, you can study the API specification and take advantage of it. Honestly, maintaining an API connection could be easier than maintaining a web scraper.
A web scraping tool can become a data console where you gather data from different websites with a series of scrapers and become a data pipeline when you connect the tool to your database. A web scraper can ignore the limit of API and extract what data you can see on the browser. Therefore, web scraping is more customizable, and when you need data from multiple sources, more powerful as an aggregator.
The disadvantages of web scraping
Web scraping is powerful, and you may have heard of some of its’ limits and wonder if you are able to deal with them. For example, during the scraping, we can get blocked by the target websites. In this section, we will have a closer look at them.
Tips:If you want to know more possible obstacles, check article 9 web scraping challenges are discussed. Octoparse has its customizable solutions to different situations. If you are stuck in any one of these issues and wonder if Octoparse can be your alternative solution, feel free to contact us at support@octoparse.com. Our colleagues are happy to help.
Start with a learning curve
Web scraping tasks can be a lot easier with a no-code web scraping tool like Octoparse since a non-coder does not have to learn Python, R, or PHP from scratch and can take advantage of the intuitive UI and the guide panel.
However, even a web scraping tool takes time to get familiar with because you have to understand the basic idea of how a web scraper works so that you can command the tool to help you build the scraper.
For example, you shall know how the data is weaved into an HTML file with different HTML tags and structures. You may learn the basics of Xpath to locate the data you need. This is also what I learned (and more) throughout my journey with Octoparse.
Your IP may be blocked
Web scraping is about frequently visiting a website or a set of web pages, sometimes clicking and sending many requests in a short period of time (so as to capture the required data on the pages). Because of the abnormal frequency, your device or IP may be detected as a suspicious robot that is executing malicious attacks on the service.
IP blocking is likely to happen when you scrape websites that are protected with strict anti-scraping techniques, such as LinkedIn and Facebook. The tracking and detection are mainly based on the IP footprint. Therefore, IP rotation or using IP proxies is an important technique for anti-blocking.
This is inevitable due to the speed of web scraping, while solutions like IP proxies and Cloud services offer a way out. Learn more about web scraping limitations.
Web scraper requires maintenance
The scraper is built to grab data according to the HTML structure. If the website you are scraping has changed its structure. For example, the data you need is moving from place A to place B, and you then have to amend your scraper to adjust to the change.
We have no control over the external website, hence only keeping up with it. As long as you get a hang of a web scraping tool, and become familiar with the anti-scraping tricks, it would be easier for you to react to these changes.
How to Start Web Scraping
There are a lot of crash courses on platforms like YouTube and Medium to teach people how to start learning web scraping with Python. But to be honest, not everyone is good at coding. If you are a total newbie in programming, you can start with a no-code or low-code method. It can be a perfect choice because you can still get the data you want without writing any line of code.
A use case is that a user needs to scrape YouTube data for marketing purposes. But she could not write a line of code. So she worked in Octoparse, a no-code web scraping tool.
Octoparse: A No-code Solution for Web Scraping
If you are looking for a way to get data with web scraping and want to start easy, a no-code tool would be a nice pick even though you are new to it. Compared with writing scripts to build scrapers, using a no-code tool like Octoparse is definitely more time-saving and effortless.
When the user we mentioned above started using Octoparse, it only took her about two weeks to get familiar with the software and learn about the basics of HTML and XPath (these can help locate elements on the page more accurately). Then she successfully built a YouTube scraper herself and got the wanted data. If you are interested in this story, you can check the article on how a marketer made use of no-code web scraping at work on Medium.
And here are some resources you may need along the way as you get onboard:
- Octoparse 101: The essential start guides for Octoparse beginners
- YouTube videos: web scraping cases with Octoparse
- TOP 10 Free Web Scrapers You Cannot Miss in 2025
What’s Driving Web Scraping in the Future
The future of web scraping is being shaped by several powerful trends:
AI-Powered Scraping:
AI-based scrapers can achieve accuracy rates of up to 99.5% when handling dynamic, JavaScript-heavy websites (Marketgrowthreports), and they’re getting smarter at adapting to layout changes automatically. What once required constant manual maintenance is becoming self-healing and adaptive.
Real-Time Intelligence:
From monitoring tariff changes in response to shifting trade policiesto tracking competitor prices during high inflation, businesses need data that’s not just accurate but current. Static datasets gathered quarterly or monthly are no longer sufficient when market conditions shift daily or even hourly.
Beyond Text Data:
By 2025, businesses increasingly require solutions that can extract complex datasets, including images, videos, and audio (Market.us). Visual data scraping and video content analysis are opening new possibilities for product cataloging, trend analysis, and multimedia marketing strategies.
Ethical and Compliant Scraping:
As data privacy regulations like GDPR and CCPA become more stringent, compliance is now non-negotiable. The successful scrapers of tomorrow will be those that respect both legal boundaries and ethical standards—using transparent data policies, proper anonymization, and responsible collection practices.
Conclusion
If you are looking for a way to get data with web scraping and want to start easy, a no-code tool would be a nice pick even though you are new to it. Compared with writing scripts to build scrapers, using a no-code tool like Octoparse is definitely more time-saving and effortless.
Whether you’re training an AI model, monitoring competitor prices, generating leads, or conducting market research, web scraping has evolved from a technical novelty into essential business infrastructure. The tools are more accessible than ever, the applications continue to expand, and the competitive advantage goes to those who can harness data faster and more effectively than their competitors.




