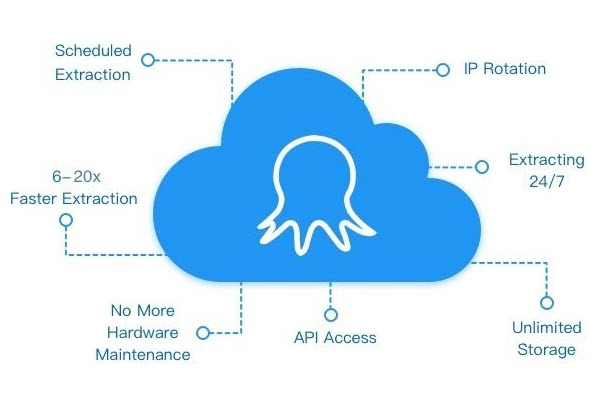
Cloud web scraping is a way to collect website data on remote servers so your crawlers keep running even when your computer is offline, asleep, or suddenly shuts down. This makes large, long-running or fragile extraction tasks faster, more reliable, and easier to scale.
If you are still running web scrapers directly on your local machine using a simple Python script or a browser extension, you have likely hit a performance wall. While local scraping works for small, one-off tasks, it becomes a bottleneck as soon as you need to scale up.
In this post, you can learn what is cloud web scraping, and how to use cloud data extraction to speed up your scraping process.
Why Local Web Scraping Often Fail:
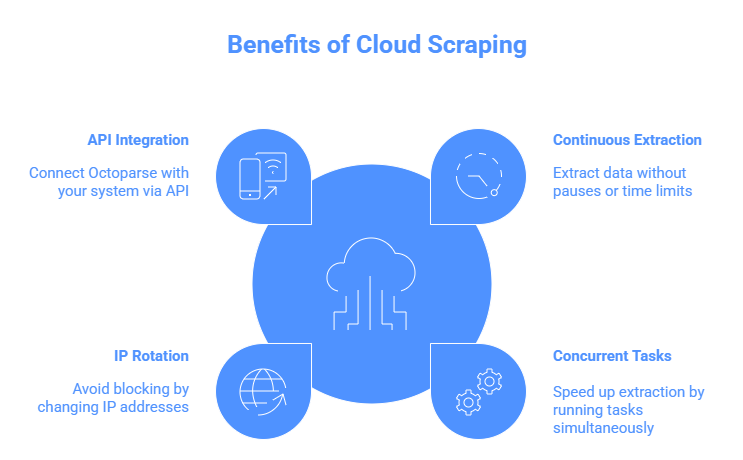
As your data needs grow from hundreds of pages to millions, local extraction often fails because:
- Hardware limitations: Your computer slows down, overheats, and consumes all your bandwidth.
- You can’t turn it off: If you close your laptop or lose internet connection, the scrape fails.
- Immediate IP blocking: Sending thousands of requests from a single home IP address is the fastest way to get banned by a target website.
- Lack of speed: You are limited to how many requests your single machine can process at once.
You can, however, take a different approach and use cloud scraping. By moving your extraction logic to a remote server environment, you gain scalability, flexibility, and cost-effectiveness. With the right setup, you can extract data from millions of pages simultaneously without using any of your own CPU power.
Cloud Web Scrapers vs. Local Web Scrapers
Cloud-based scrapers and local scrapers represent two distinct approaches to web scraping. While choosing an option between them, companies might weigh factors like speed, scalability, reliability, maintenance, cost, etc., to determine the most suitable approach for their web scraping requirements. Here are some key differences between cloud web scrapers and local web scrapers.
| Features | Cloud-based | Local-based |
|---|---|---|
| Speed | faster for large-scale scraping tasks | Might be slower for extensive scraping operations, especially when dealing with high volumes of data |
| Scalability | Scale up or down based on the volume of data to be scraped | Limited by the computing power and resources available on the local machine |
| Reliability | More reliable due to the robust infrastructure and redundancy measures offered by service providers | May face interruptions due to network issues, machine failures, or other local constraints |
| Maintenance | Require minimal maintenance as the cloud provider handles infrastructure management, updates, and backups | Need more hands-on maintenance, including updating scripts, monitoring performance, and managing local resources |
| Cost | May incur costs based on usage, but they eliminate the need for upfront hardware investments and can be cost-effective for large-scale scraping operations | Generally more cost-effective for smaller-scale scraping tasks as they do not involve additional cloud service expenses |
| Control | Offer less control over the underlying infrastructure than local scrapers, limiting customization options | Provide more control over the scraping process, enabling users to fine-tune scraping scripts and adapt to specific website structures |
What is Octoparse Cloud Extraction Mode
So far, we’ve known the strength of cloud-based web scraping. There are many cloud web scrapers in the market, and Octoparse is the most recommended one because of its powerful functions.
Octoparse allows you to build the scraper logic on your local desktop client and then “push” that task to their cloud platform.
Octoparse utilizes a distributed computing method. When you upload a task to their cloud, the platform splits your list of URLs and assigns them to multiple cloud servers simultaneously.
- Speed: If a task takes 1 hour on your local machine, splitting it across 6 cloud servers could finish it in 10 minutes.
- Rotation: It handles the IP rotation automatically within the cloud environment.
- Scheduling: You can set the task to run automatically at specific intervals.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
Octoparse also offers a powerful cloud function that allows users to run their tasks 24/7. While running tasks using Octoparse cloud servers, you can speed up scraping, avoid being blocked with a huge number of addresses, and link your system and Octoparse closely with API.
Here are some features of why choosing Octoparse for cloud data extraction.
Extract data without any pauses and time limit
While using the Octoparse cloud service to pull data from websites, no concern for errors like occasional network interruptions or the computer being frozen anymore. When such errors occur, cloud servers can still resume their work immediately. Meanwhile, if you need to extract data at a specified time or update your data following a routine, you can schedule a cloud extraction task via Octoparse.
Set concurrent tasks to speed up the extraction process
As mentioned above, cloud platforms allow you to divide a scraping task into several sections and assign them to multiple servers to extract data at the same time. Octoparse Cloud mode now provides up to 20 nodes for paid plans. While extracting data with the Octoparse cloud platform, Octoparse will try to split up your task into smaller sub-tasks and run each sub-task on a separate cloud node for faster data extraction. The cloud nodes can run tasks 24/7 and reach up to 4-20 times faster than local extraction.
Avoid being blocked by IP rotation
If you’re experienced in web scraping, you might have been blocked by websites while scraping data. Being blocked is a common problem for scrapers, because many websites may have high-security measures to recognize and block web scrapers. To solve this problem, the Octoparse cloud service provides thousands of cloud nodes, each with a unique IP address, for IP rotation. So your requests can be performed on the target website through various IPs, which will minimize your chances of being traced and blocked by the target website.
Link Octoparse and your system via API
Octoparse cloud service also provides you API to link your system or other tools and Octoparse closely, so you can export scraped data into your database directly rather than spending time exporting data files to your devices first. For example, you can export extracted data to Google Sheets via Octoparse API. Or if your team has coding experience and needs to automate the process to export data or control tasks, you can connect to Octoparse APIs with Postman.
How to Use Octoparse Cloud Data Extraction Step-by-step
Cloud extraction mode is the advanced function of Octoparse; please make sure you have subscribed to the Octoparse Standard/Professional/Enterprise plan already. Then, launch your Octoparse on your device and follow the steps below.
Step 1: set up your extraction task
Similar to the local scraping mode, you should set up your workflow first. Copy and paste the target website you want to scrape. With Octoparse’s point-and-click interface and auto-detecting function, you can easily create a scraping workflow.
Step 2: customize your data scraping workflow
Check and specify the data fields you need, like product details, prices, reviews, etc. You can set up pagination, Xpath, IP proxy, and other advanced features in this step. Delete or add data fields according to your needs.
Step 3: run your task in the cloud
After finishing the workflow, click on the Run button and select Standard Mode or Boost Mode under Run in the Cloud to execute a run in the cloud. There’s no need to keep your computer on or worry about performance.
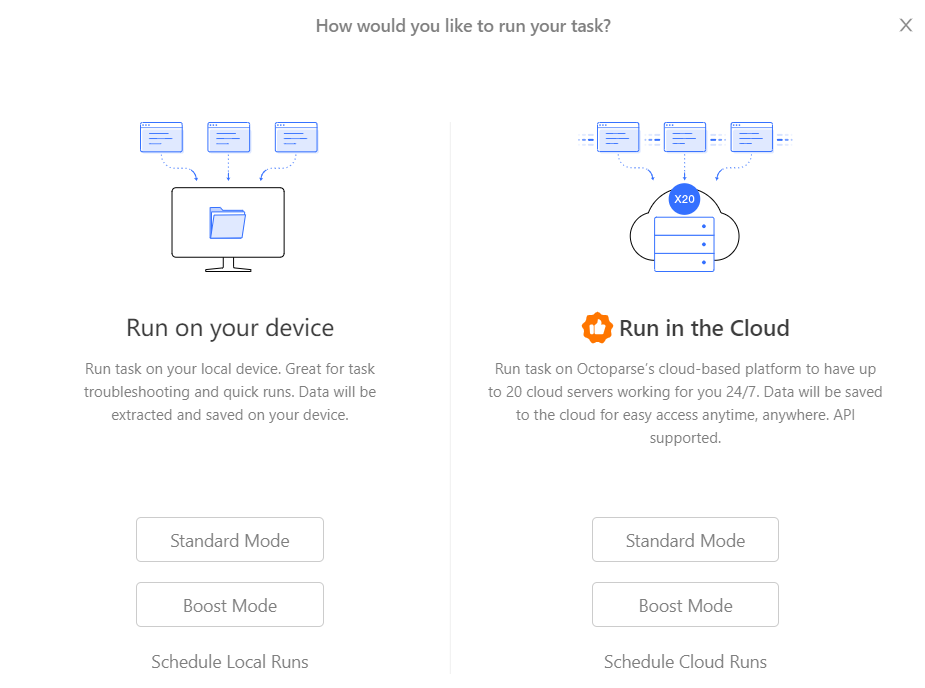
You can also run multiple tasks from the cloud simultaneously. Select any tasks that need to be run from the Task List, and click on Start Cloud Run to run them together in the Cloud.
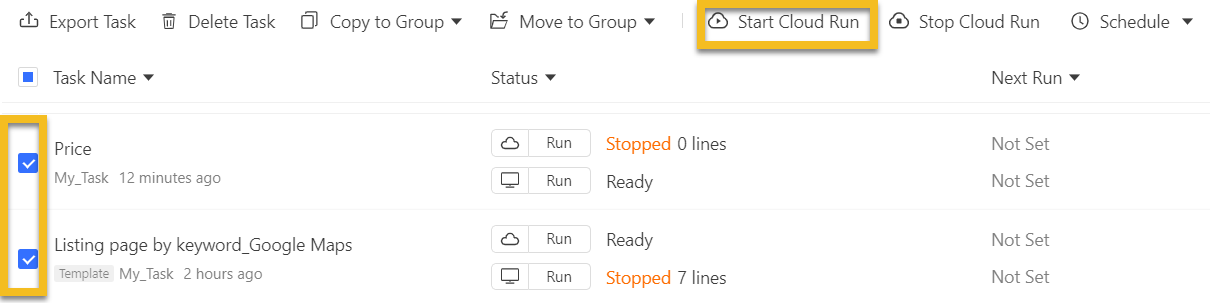
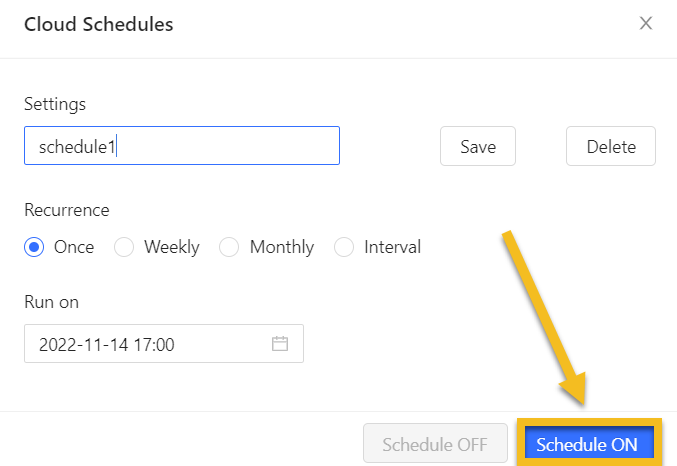
Scheduling the cloud scraping at any time is allowed. Choose the Schedule Cloud Runs for a single task, and click on the Schedule ON button to set the scheduling time.
For more details settings about Octoparse cloud scraping, you can move to the Cloud Data Extraction Tutorial to read more.
Wrap Up
Cloud-based web scraping is the solution to simplify your data extraction process. Compared with the local-based solution, it’s more effective and can help you address common problems like being blocked and CAPTCHA. Try Octoparse cloud scraping mode now. Let cloud servers bring your web scraping journey to the next level!