Price scraping is the automated collection of pricing data from websites. A tool or script visits product pages on a schedule and records their prices into a structured file. Most guides stop at “here are ten tools.” This one goes further. The hard part is rarely getting a number, it’s getting the right number, and that’s where most price monitoring projects quietly fail. By the end, you’ll know which method fits you, how to set one up, and how to avoid the bad-data traps no tool comparison warns you about.
Which price scraping method fits you?
Before the deep dive, here’s the quick answer. Five common ways to track competitor prices, and who each one is actually for:
| Method | Best for | Coding needed | Cost to start | Watch out for |
|---|---|---|---|---|
| Octoparse (no-code visual + templates) | Non-coders tracking 50–10,000+ products on a schedule | None | Free plan, paid for cloud/scale | Built for scheduled runs, not sub-second real-time |
| Import.io | Teams already in its ecosystem, quick table-style extraction | Low | Free tier (tight limits) | Dated desktop app, steeper learning curve |
| Scraping APIs (e.g. proxy/scraper services) | Developers who want to build and maintain their own pipeline | High | Usage-based | You engineer parsing, retries, and monitoring yourself |
| Browser extensions | One-off, single-page price checks | None | Usually free | Not built for scheduled, multi-page monitoring |
| Custom Python script | Engineers with edge-case sites and time to maintain | High | “Free” (your time) | Breaks on layout changes, ongoing maintenance |
If you’re a retailer or seller who wants clean, scheduled data without writing code, a no-code tool like Octoparse is the fastest path. If you’re a developer building price intelligence into a product, an API or your own script makes more sense. The rest of this guide assumes the no-code route but flags where developers diverge.
What Is Price Scraping, and How Does It Work?
Price scraping is exactly what it sounds like. You tell a tool which pages to visit and which numbers represent prices, and it visits those pages on a schedule and records what it finds. The reason you’re reading about it instead of just doing it is that execution gets tricky fast. Prices are buried inside pages full of images, reviews, and promo banners, and extracting just the price reliably across hundreds of products takes either real technical skill or the right tool.
The scale of the problem is what makes it worth solving. Amazon implements more than 2.5 million price changes a day, roughly one change every ten minutes on competitive items, while large retailers run entire teams to keep up. You don’t need a team. You need a system, and that system starts with price scraping.
One distinction matters before you start. Scraping publicly visible prices the way a customer would browse is well-established and generally low-risk. Abusing access, by hammering servers, harvesting personal data, or bypassing login walls, is where you cross a line. (More on the legal picture in the FAQ.) That practitioner’s view of how to scrape prices responsibly is something the anti-scraping vendors writing “price scraping is a threat” guides will never give you.
Why Can’t I Just Use an Official API?
This is usually the first question, and it’s the right one to ask.
When people first explore price monitoring, they Google something like “Amazon API pricing data” hoping for an easy answer. And technically, Amazon does have an API—the Product Advertising API.
But here’s the catch: that API is designed for affiliate marketers, not competitive intelligence. It doesn’t expose real-time pricing for most products. It has strict rate limits. It requires you to drive qualifying sales to maintain access. And it only covers Amazon.
This pattern repeats everywhere. Walmart, Target, Best Buy—most major retailers either don’t offer public APIs or lock them behind partnership agreements. The prices you can see as a shopper aren’t available through any official channel.
This gap between “I can see it on the website” and “I can access it programmatically” is exactly why price scraping exists.
What Makes Price Scraping Difficult?
Here’s what no tool comparison tells you. The difficult part of price scraping isn’t grabbing a number off the page. It’s grabbing the correct number. A single product page often shows several different “prices” at once, and a naive scraper picks the wrong one.
Take a typical Amazon product page. On it you might find, all at the same time:
- a list price (the struck-through “original” price)
- a deal or sale price (what’s actually being charged today)
- a coupon or member price (shown only after a clip or login)
- a third-party seller price or a “from $X” range when multiple sellers compete
- an installment / monthly payment figure (“$24.99/mo”)
Auto-detection is genuinely useful, but on messy layouts it commonly mis-fires, grabbing the struck-through list price or the monthly installment figure instead of the real selling price. If you don’t catch it, your “competitor price” database silently fills with numbers that were never the actual price.
The fix is to stop treating “price” as one field. In a visual tool like Octoparse, you define separate fields for sale price, original price, and seller price, and capture each one explicitly rather than letting the tool guess which is “the” price. You can also decide up front how an out-of-stock or unavailable item should be recorded (an empty value versus a placeholder string), so a missing price doesn’t masquerade as a real one. It’s five extra minutes of setup that saves you from weeks of quietly corrupted data, and it’s the single highest-leverage habit in price scraping.
Top 3 Price Scrapers You Cannot Miss

(Feel free to use this infographic on your site, but please provide credit and a link back to our blog URL using the embed code below.)
1. Octoparse
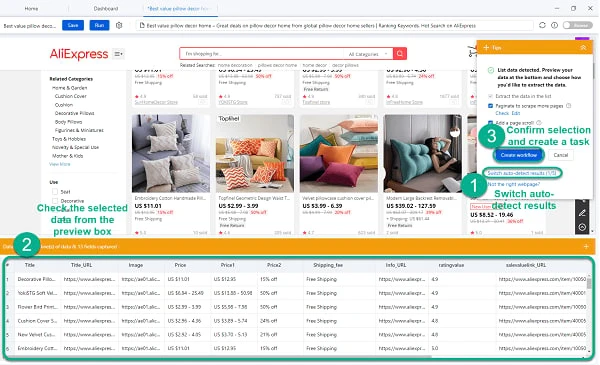
Octoparse is your best choice for price scraping. You can use it to scrape price data from most e-commerce websites, like Amazon, eBay, AliExpress, Etsy, Priceline, etc., and grab other information including product descriptions, ratings, reviews, and comments from these platforms. Users don’t need to know how to code because Octoparse provides the auto-detecting function and preset templates which help to scrape price data without coding needed.
However, Octoparse also provides advanced functions like IP proxies, CAPTCHA bypassing, cloud scraping, scheduled scraping, and more to help you get precious data or large-scale data.
Method 1: Price scraping templates for hot sites
Octoparse provides a set of data scraping templates for popular E-commerce websites, including Amazon, eBay, Etsy, Flikpart, and others. With these templates, you just need to enter several parameters to start scraping price data. Try the following online price scraper to get Amazon price data.
https://www.octoparse.com/template/amazon-product-details-scraper
Method 2: Scrape price data with Octoparse manually
If the preset templates cannot meet your scraping needs, then you can customize your price monitoring by creating a crawler manually with Octoparse. Download Octoparse and follow the simple steps below to start.
Step 1: Copy and paste the target price page link.
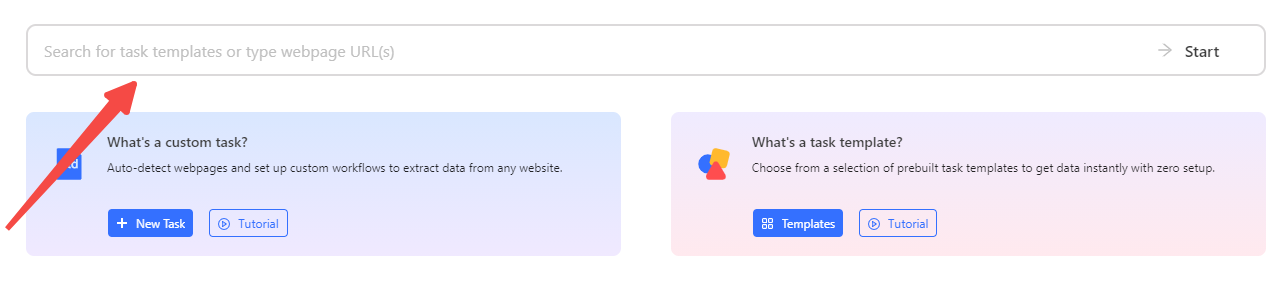
Go to the web page you want to scrape, and enter the URL you want to scrape into the URL bar on the homepage. Click the Start button.
Step 2: Set the price data fields.
The auto-detection will start, and the price areas can be recognized automatically. Create a workflow after the auto-detection finish. Preview the data fields and make changes by using XPath, setting pagination, adding or deleting data fields, etc. The Tips panel will give you prompts to help you continue.
Step 3: Start scraping price data.
After all scraping settings have been checked, you can click on the Run button to start extracting data from the website. You can choose the local scraping mode or the cloud scraping mode to set a scheduled time you want.
Step 4: Download price data into Excel.
You can download the scraped data into any format you want, such as Excel, CSV, Google Sheets, etc. The database can also be connected with Octoparse.
2. Import.io
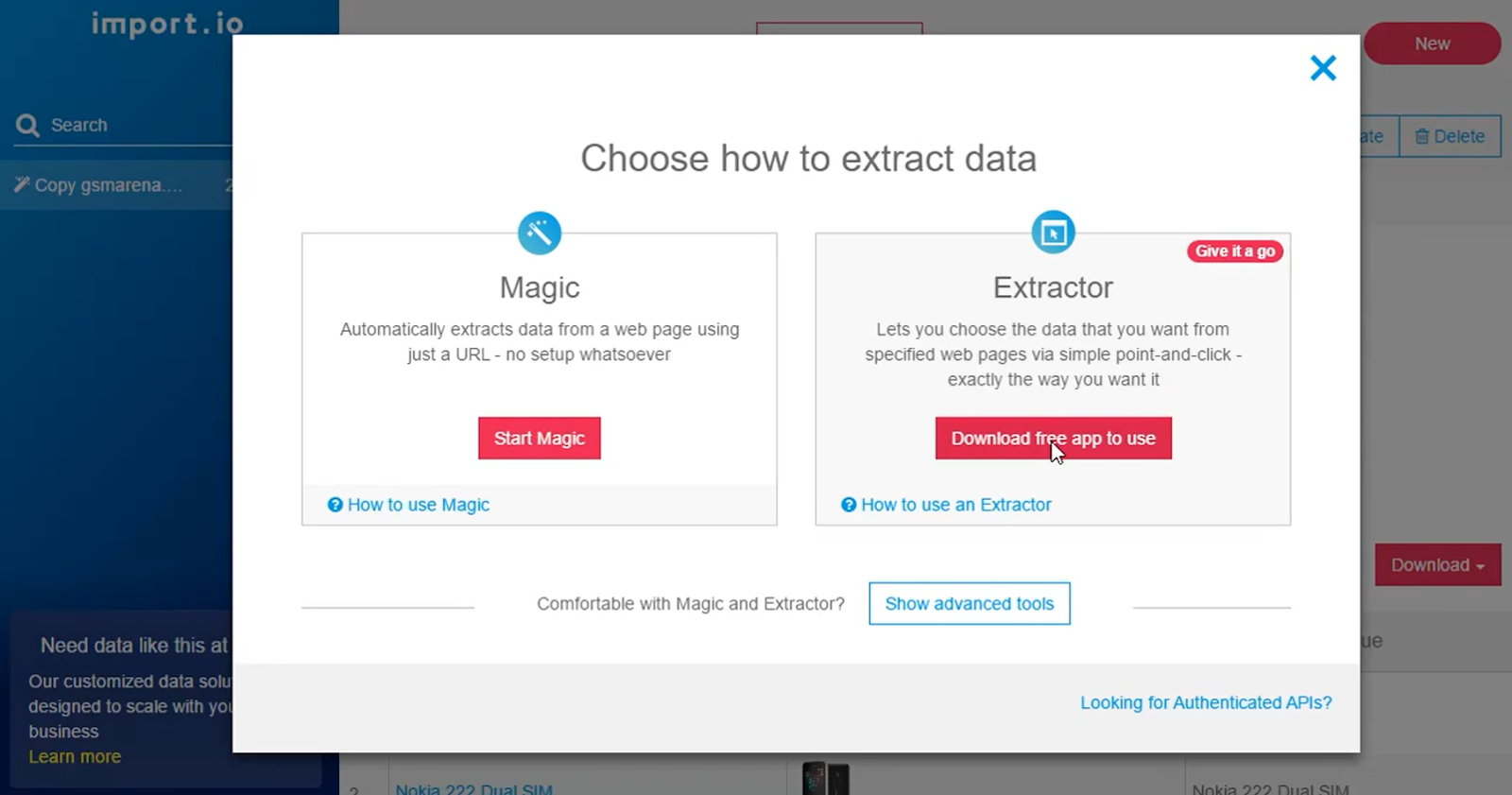
Import.io has been around longer than most visual scraping tools, and it shows—both in good ways and bad.
The “Magic” import feature is impressive when it works. You paste a URL, and it attempts to convert the page into a structured table automatically. For simple pages with clear tabular data, this can be faster than Octoparse’s workflow. I’ve had good results on simpler e-commerce sites and product listing pages.
The integration options are solid. Google Sheets, Excel, and direct API access all work as advertised. If you’re building a workflow that needs to pull data programmatically, Import.io’s API is well-documented.
What frustrated me: the desktop app.
For anything beyond basic pages, Import.io pushes you toward downloading their application, and the experience there feels dated compared to browser-based tools. The learning curve is steeper than it needs to be, and I found myself checking their tutorials more often than I’d like.
Pricing is also worth mentioning. They advertise a free tier, but the limits are tight enough that any serious price monitoring project will hit them quickly. The jump to paid plans is significant.
I’d consider Import.io if you’re already in their ecosystem or if their Magic tool happens to work well on your specific target sites. For starting fresh, I think there are easier paths.
3. ScrapeBox
ScrapeBox is a different animal entirely. It’s a desktop application that’s been a staple in the SEO community for over a decade, and it can technically be used for price scraping—but that’s not really what it’s built for.
The strength of ScrapeBox is bulk operations: harvesting URLs, checking page ranks, verifying proxies, scraping search results at scale. SEO professionals and marketers use it for competitive research, link prospecting, and (historically) some gray-hat tactics I won’t get into.
For price monitoring specifically, you can make it work, but you’ll be fighting the tool. There’s no visual point-and-click for defining price fields. You’re working with patterns and configurations that assume you know what you’re doing. The proxy management is powerful—thousands of rotating IPs—but setting it up requires real effort.
I wouldn’t recommend ScrapeBox as your first price scraping tool. But if you’re already using it for SEO work and want to add price monitoring without adopting another platform, it’s capable enough. Just expect to spend time configuring rather than extracting.
For a deeper comparison of price monitoring options, see: Best Price Monitoring Tools
How Do I Get Started With Price Scraping?
Here’s what the first week actually looks like, as a five-step loop.
- Define what you’re tracking. Not every product deserves monitoring. Focus on bestsellers, high-margin items, and products where you’ve lost sales and suspect price was the reason. Fifty to a hundred products is plenty to start, and you can always expand later.
- Gather the URLs. For Amazon, that’s product detail pages (the URLs with
/dp/and an ASIN, the Amazon Standard Identification Number). For other retailers, it’s whatever page shows the current price. Collect them manually or export them from your inventory system. - Paste a URL, auto-detect, and verify the right field. Let the tool scan the page, then confirm it grabbed the actual selling price, not the struck-through original or the monthly installment (see the section above). This one check is the difference between clean and corrupted data.
- Run it, review the output, fix what broke. Your first extraction will probably have issues. Some pages fail, some prices pull wrong. That’s normal. Adjust the configuration based on what you see.
- Schedule it and connect the output. Once it runs reliably, automate it. Daily is the most common frequency. Pipe the results to a Google Sheet, dashboard, or your pricing system. (Octoparse’s e-commerce templates handle steps 2–3 for popular sites out of the box.)
Comparing prices across countries? You’ll scrape “£299” from a UK site, “€349” from Germany, and “¥44,800” from Japan, then need to compare them. The cleanest approach is to store the raw price and its currency code exactly as scraped, then convert to your base currency at analysis time using that day’s exchange rate. That preserves the original data and lets you re-run comparisons later with updated rates. One trap: the displayed price isn’t always what a local customer pays. VAT (value-added tax) inclusion varies by country, so a “€349” tag might bill a German buyer €349 but a French buyer more after tax. For most competitive intelligence, same-currency comparisons within a single market are more actionable than perfectly normalized global pricing.
How to Scrape Prices at Scale without Getting Blocked?
Price monitoring has a built-in tension. Its whole value comes from hitting the same batch of pages every single day, which is precisely the pattern anti-bot systems are tuned to catch. Three habits keep you under the radar.
Control your request rhythm. Don’t fire every SKU at once. Randomized delays and limited concurrency make automated collection look more like a human browsing and less like a flood. Scrape like a customer would, just on a schedule.
Distribute requests with IP rotation or cloud scraping. Many requests from one IP is the fastest way to get blocked. In Octoparse specifically, the free plan runs locally only. IP rotation and residential proxies are bundled into the paid and cloud plans, where cloud scraping spreads a task across multiple rotating IP nodes instead of one machine. This isn’t just a paywall quirk. Among recent Octoparse users, paid accounts use cloud-based scraping at roughly four times the rate of free users (about 73–78% versus 17–22%), a clean signal that cloud scraping is the feature separating casual users from people running serious, recurring monitoring.
Monitor task health. Don’t schedule a scraper and forget it. Set alerts for when a run returns zero results, when data volume drops sharply, or when a value lands in an impossible range. A “$0.00” or “$999,999” should raise a flag, not silently enter your database. (For how rotating IPs actually prevent bans, see how proxies prevent IP bans in web scraping.)
What Can You Actually Do With Price Data?
Collecting data feels productive, but data sitting in a spreadsheet doesn’t help anyone. The value comes from what you do with it.
The ROI is measurable. According to research from QL2, one office supply retailer calculated a 260% return on their competitive intelligence investment—$2.60 back for every dollar spent on price tracking. McKinsey research suggests companies using data-driven pricing strategies see 10-15% increases in margins and 5-10% boosts in sales.
But you don’t need complex analytics to capture value. Here’s what basic price data enables:
Understand where you actually stand. Are you the cheapest option on your bestsellers? The most expensive? Somewhere in the middle? Without data, you’re guessing based on the last time someone manually checked. With daily data, you know exactly where you’re positioned on every product.
Catch competitor promotions early. Your competitors don’t send you press releases when they drop prices. But if you’re tracking their pages daily, you’ll see a 20% price cut the same day it happens. That gives you time to decide: match it, ignore it, or run a counter-promotion.
Spot trends before they hurt you. A single price change is noise. A competitor systematically lowering prices across a category over three weeks is a strategic signal. You can only see that pattern if you have historical data.
Negotiate better with suppliers. When you’re asking for better margins, showing vendors what competitors charge at retail strengthens your case. “The market price is X” is more persuasive when X comes with a chart.
Feed smarter pricing systems. If you’ve graduated to dynamic pricing—or you’re considering it—competitor data is essential input. You can’t price intelligently in a vacuum.
Notice that none of this requires fancy analytics. A spreadsheet with thirty days of competitor prices, refreshed automatically, supports all of it.
A European B2B holding company managing roughly 50 portfolio companies replaced gut-feel pricing with automated weekly competitor scraping. They pulled article numbers, units, and prices, then fed data-backed formulas (for example, the median of three competitors’ prices times a multiplier) into their pricing system. Before, as their commercial team put it, they were talking about “market price” with no actual market data behind it. In their experience, moving to data-driven pricing typically yields a 2–4% improvement in profit margins.
FAQs
Is price scraping legal? Scraping publicly visible pricing for competitive research is generally low-risk but not zero-risk. Terms of service matter. Many sites prohibit scraping, and violating those terms can in theory create civil liability, though enforcement against reasonable business research is rare. The safe principle is to scrape like a customer would browse, don’t collect personal data, and don’t bypass login walls. For the full picture, see is web scraping legal?
Can I scrape prices from websites that require login? Technically yes, and most visual tools, including Octoparse, support authenticated scraping. But the legal picture shifts. Behind a login you’ve agreed to terms that almost certainly prohibit automated collection, so you’re no longer in “public data” territory. The line is whether you’re automating access you legitimately have, such as your own supplier or wholesale portal, versus using credentials you shouldn’t. If B2B pricing intelligence is critical and you’re unsure, that’s a lawyer question.
What do I do when my price scraper breaks? Every scraper breaks eventually, usually because a site redesigned, added anti-bot measures, or changed a page when a product went out of stock. With a visual tool you check the task log, see which element failed, and re-point the selector, a roughly fifteen-minute fix. In a custom script you’re digging through HTML changes and updating patterns, often an afternoon. Either way, budget about an hour a week to spot-check data quality and update selectors before small drifts become full failures.
How often should I scrape competitor prices? It depends on your market’s pace. Fast-moving categories and flash-sale periods may warrant hourly checks. Most retailers do fine with daily, and slow-moving B2B catalogs can run weekly. Match frequency to how fast prices actually move. Over-scraping adds block risk and noise without adding insight.
Is free price scraping software good enough for a small store? Often, yes. For tracking 50–100 products on a daily schedule, a free plan typically covers it. There’s even data suggesting “free and adequate” wins for many users. When one popular free template was upgraded to a more capable paid version, monthly users actually dropped 44%, a sign that a meaningful slice of people prefer free-and-sufficient over paid-and-better. You’d move to paid mainly for cloud scheduling, IP rotation, and higher volume.
What’s the difference between price scraping and price monitoring? Price scraping is the collection step, extracting prices off web pages. Price monitoring is the ongoing practice of scraping on a schedule, tracking changes over time, and acting on them. Scraping is the engine. Monitoring is the program you build around it. For a roundup of dedicated monitoring tools, see our price monitoring tools guide.
Final Thoughts
There’s no universally “best” price scraper. The right choice depends on who you are and how big you’re operating. A solo retailer tracking a hundred SKUs and an engineering team feeding a pricing engine need different things. If you’re tracking competitor prices regularly and want clean, scheduled data without writing code, start with Octoparse for free. Its 600+ templates and free plan get you to working data in an afternoon, and you can scale into cloud and API access when monitoring becomes part of daily operations.