Job aggregators are effective tools for job seekers to find relevant career opportunities and keep track of other important information about jobs, such as location, industry, salary level, etc. Setting up a job aggregator needs sufficient data on job posts, making web scraping an essential means for aggregating position information. In this post, we’ll show you how to extract data for job aggregators.
What are Job Aggregators
You might have heard names of famous job boards, like ZipRecruiter, which provide users with general postings available in a searchable format. In general, you can search for job opportunities for a specific industry to narrow and tailor your search on a job board. Job aggregators share some of the advantages of job boards somehow, and show strengths in providing sources from various sources.
A job aggregator, in short, is a one-stop hub where job openings from everywhere online can be easily searched and compared to help connect talent with opportunities. Job aggregators are the aggregating tools for both job seekers and companies. A good aggregator, taking major aggregators like Indeed and LinkedIn Jobs as examples, should have a huge and comprehensive job database for users to filter by location, industry, keywords, and other criteria.
You can find more job posting data from the top 10 job information sites so that you can scrape and re-organize them for your further use.
What Role is Web Scraping in Job Aggregation
As mentioned above, data from job posts is the building block of any job aggregator. Without sufficient data from diverse sources, a job aggregator can not provide core functions of centralizing information in a location. Because web scraping can pull data from websites, web scraping plays an important role in job aggregation to avoid such problems.
Web scraping is a technique that applies a bot or web crawler to copy specific data from the pages into a database or spreadsheet. While you might copy and paste data online to a local file manually, web scraping improves the efficiency of collecting information and allows you to extract data in bulk with fewer human errors.
Another important role of web scraping in job aggregation is that it can contribute to an up-to-the-minute collection of job openings. Because the status of job posts is fast-changing on most pages, tracking new and updated postings is crucial for timing your job aggregators. Web scraping, in this context, can scrape job listings from thousands of sources repeatedly to populate your database and automate the process of detecting and importing fresh listings.
How to Scrape Job Posts Efficiently
Collecting job posts with web scraping is an effective but not easy method. For example, if you’re new to web scraping and have no skills in coding, you might find writing scripts for data extraction has a steep learning curve. Even expert might have faced some challenges, like the anti-scraping feature that can block their IPs and slow down the speed of scraping data.
To solve such problems, many service providers have launched a variety of no-coding web scraping tools. These tools are designed for anyone regardless of programming skills. Taking Octoparse as an example, this solution can turn job posts on the pages into structured data within clicks. It has features, like auto-detection, task scheduling, automatic export, IP rotation, CAPTCHA solving, etc., to simplify the data extraction process and avoid blocking.
Besides the no-coding web scraping tools, you can try different means based on your specific needs and coding skills. Python and web scraping APIs are also well-used for grabbing job posts. You can check out our TOP list of web scraping tools for extracting job posts to find the right one.
Four Steps to Scrape Data for Job Aggregators
Now, we’ve seen how important web scraping is for job aggregation. In this part, we’ll walk you through how to scrape job posts for job aggregators with Octoparse. Building a job scraper with Octoparse will only take four steps, so you can spend most of your time in other sections of setting up a job aggregator, such as creating the front end and developing the posting flow.
If this is your first time scraping job postings, please download Octoparse for free and install it on your device. Then, you can sign up for a new account or log in with your Google or Microsoft account to unlock the powerful features of Octoparse.
Step 1: Create a new task for scraping job postings
Copy the URL of any page you want to scrape job postings from, then paste it into the search bar on Octoparse. Next, click “Start” to create a new task.
Step 2: Auto-detect details of jobs on the page
Wait until the page finishes loading in Octoparse’s built-in browser (it might take seconds), then click “Auto-detect webpage data” in the Tips panel. After that, Octoparse will scan the whole page and “guess” what data you’re looking for.
For example, when you try to scrape job postings from Indeed, Octoparse will highlight job title, company name, location, salary level, job type, posted day, etc., on the page for you. Then you can check if it has selected all the data you want. Also, you can preview all detected data fields in the “Data Preview” panel at the bottom.
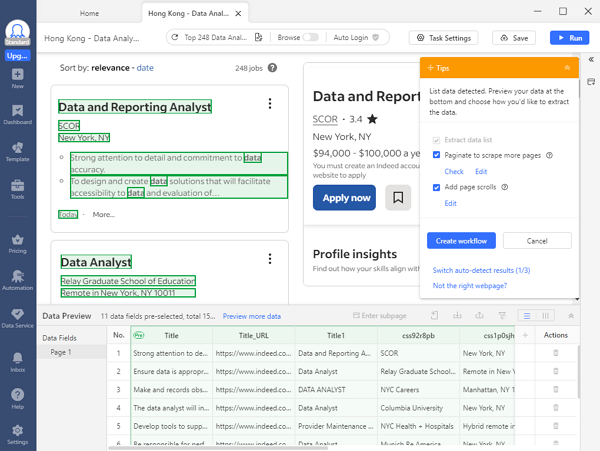
Step 3: Create the workflow for job scraping
Once you’ve selected all the wanted data, click “Create workflow” in the Tips panel. Then, an auto-generated workflow will show up on your right-hand side. The workflow shows every action of the job scraper. By reading it from top to bottom, you can easily understand how your scraper works.
Also, you can click on each action of the workflow to review if the action works as expected. If there is any action doesn’t work, you can remove it from the workflow and add new actions to modify it and get the job data you need.
Step 4: Run the task and export the scraped job data
After you’ve double-checked all the details, click the Run button to launch the task. You can run it directly on your device, or hand it over to Octoparse Cloud Servers. Compared with running the scraper locally, the Octoparse cloud platform is a perfect choice for huge tasks, and cloud servers can work for you around the clock. Then, you can get up-to-date job postings for your job aggregators.
When the run is completed, export the scraped job postings to a local file like Excel, CSV, JSON, etc., or a database like Google Sheets for further use.
Wrap UP
Web scraping is a must for job aggregation. It’s impossible to set up a trusted and up-to-date job aggregator without the help of web scraping tools. No-coding web scraping solutions can simplify your process of collecting job postings so that you can spend most effort and time on setting up and modifying the job aggregator. Give Octoparse a try, let web scraping fuel job aggregation.