As information gets hard to crawl, the jobs needing to be done involve more complexity and effort. People have started to investigate tools that can free them from this information hunt. Yet with so many different tools advertising their magical capability, it’s normal to be confused. But hey, don’t worried, this article is here to clear the cloud and present you with comprehensive analysis and comparison.
Factors to Be Considered Before Choosing A Scraper
Of all the existing scrapers online, there are 5 main types: SaaS, DIY scraper, API, one-stop solution platform, and brower extension. Each of them shows strength in a certain field. Before you choose which to start, it’s better to consider the following factors.
- Programming Background
It’s sure that the infrastructure of scrapers is built by programming language and if you are a developer yourself, it will save you a lot of learning effort to master the trick of it. But don’t worry if you don’t have a clue about such knowledge, there will still be tools designed to meet your need below.
- Data Volume
Which tool you should choose greatly depends on how large the data you want, since some tools are just built for easy daily scraping. Make a rough guess of your needed data volume. Is it just bytes or kilobytes or are we talking about giga- or even terabytes here?
- Data Input & Ouput
Knowing what kind of data you are going to scrap and what kind of format you want to receive back from the scraper also helps simplify the choosing. Scrapers are built specifically to solve one or several of data types such as HTML, JSON or XML. And if you want to scrape some media information like images and videos, keep that in mind and narrow the keyword scopes. For data output, though many scrapers offer formats like Excel, CSV, JSON, XML, it’s also worth noticing if it supports importing into database like Google sheet, SqlServer, MySql or API as well.
- Scraping Intervals
How often do you need to extract data from targeted sources? Is it a one time scraping or regular scraping?
- Scraping Complexity
Will you need to use another IP address in order to access the geo-restricted inforamtion, or even rotate your IP if necessary to avoid blocking? Many websites now develop anti-scraping technology such as CAPTCHAs to block some scrapers behind the wall, so make sure your chosen tool get to handle that too. Account rate limits is also a factor to be taken into account, which is a cap on how often someone can repeat an action within a certain timeframe.
Having these factors in mind will help you filter faster those scrapers recommended below. Here we go!
No-coding Required Scrapers
No more dilly dallying. I know what you are thinking. Getting the job done in the simplest way with as fewer setup and maintenance as possible. For SMBs who don’t have a developer or someone who hasn’t learned programming before, SaaS will be the perfect solution to put your mind at ease. It handles maintenance and enables you to scale your projects if necessary, not to mention there is free plan available.
Octoparse
Octoparse delivers a suitable no coding solution in this regard. Yes, you hear me, no coding. Bless marketeers. Its simple interface and easy point’n’click design help you navigate, choose and edit the area where you extract your information just like when you are browsing the page.
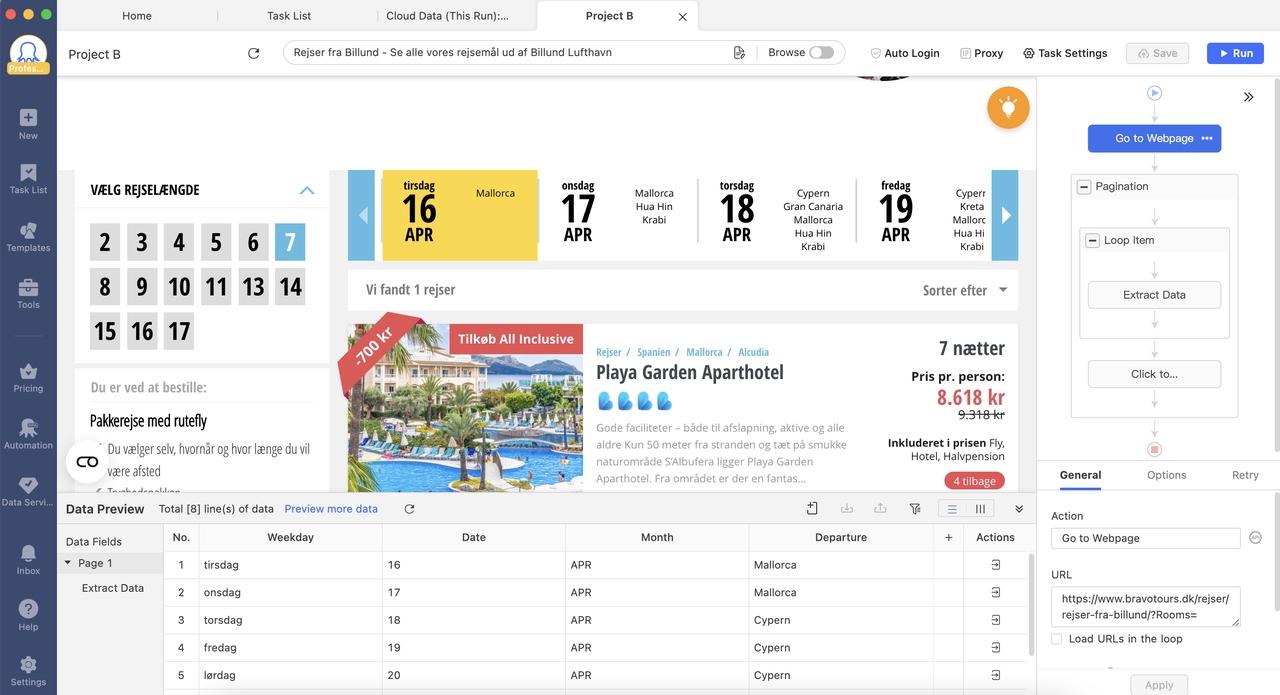
When the workflow is done, you can decide if it is a one-time scraping or a regular one by scheduling a recurrence at an interval(weekly, monthly or even several minutes to crawl near-real-time data).
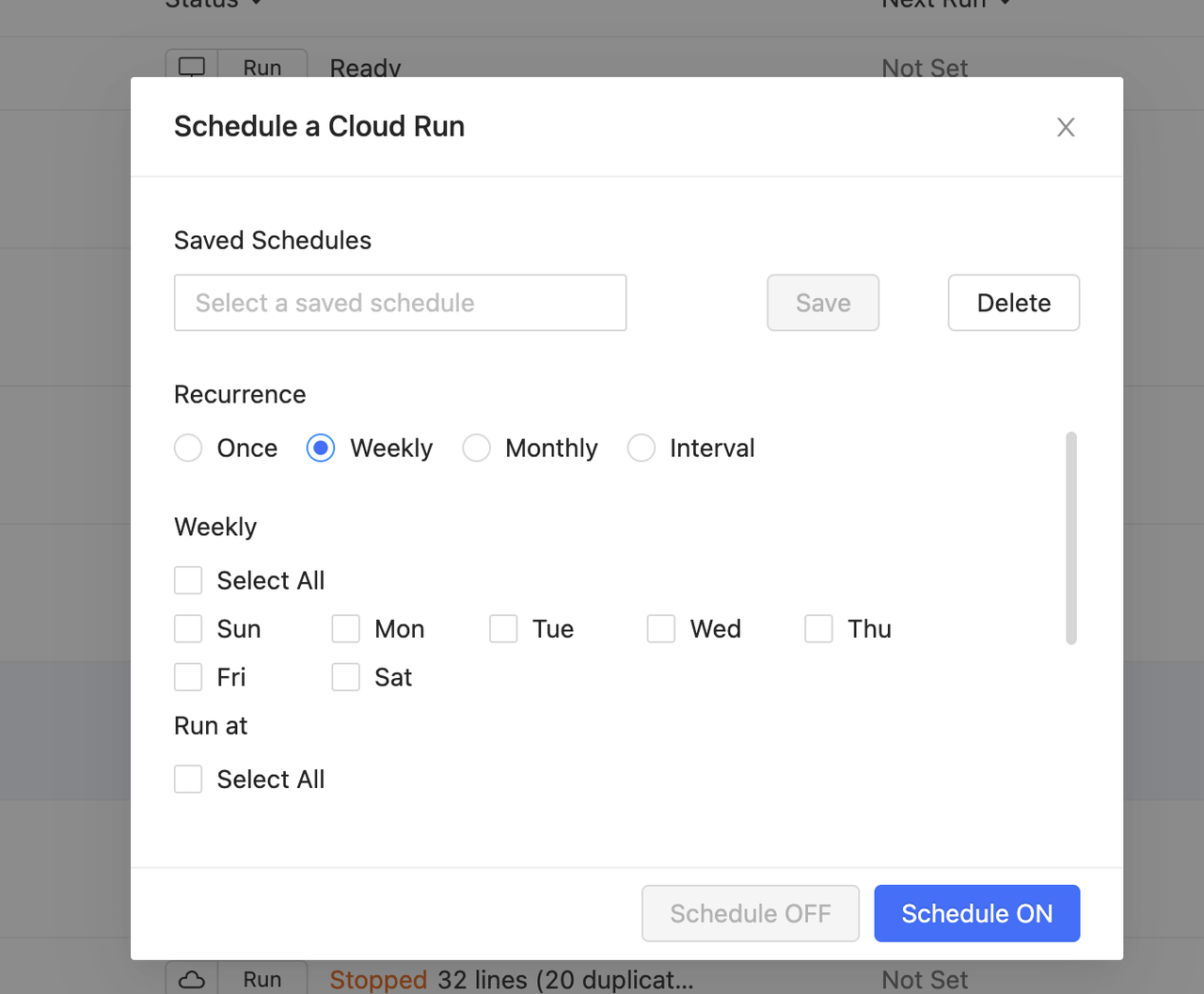
It also supports Cloud Run to reduce strain on your own server and leave you to do what matters. Additional services such as Proxies, IP rotation and CAPTCHAs solving are provided. There are also templates covering the majority of the hottest websites for you to use. All you need is to enter several parameters and the process is off to go. Customization is also available and ready to be connected to your workflow and database.
Except for general purpose scrapers like Octoparse, there are scrapers that focus on SEO. For example:
Screaming Frog and Scrape Box
The former Screaming Frog provides comprehensive solution for SEO site audit. Its services range from broken links finding, page titles & meta data analysis, XML sitemaps, JavaScript websites crawling to rediects audit.

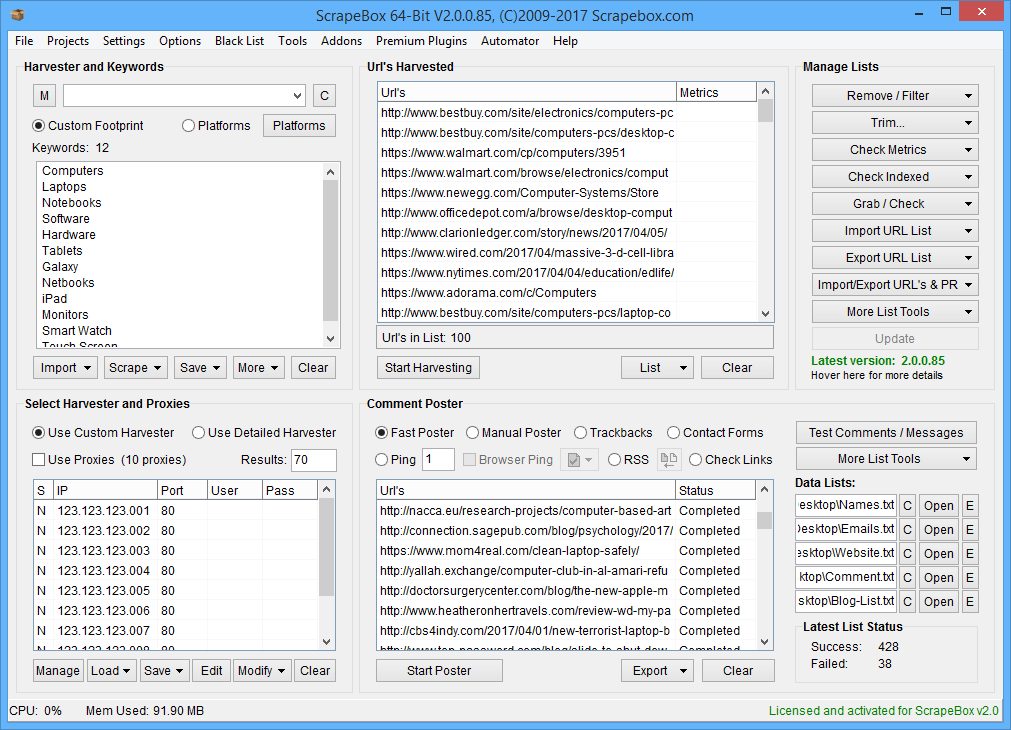
While Scrapebox also focuses on SEO, it emphasizes on different areas. You can get a batch of links that are related to your keywords and niche by scraping more than 30 search engines. And you can also build mass backlinks with its trainable poster, which can help you leave comments on dozens of blog platforms. If you are finding long tails for your next blog idea, Scrapebox is here to help too. With all the features of SEO, it also surprised me with Youtube Video Download and email scraper. Not bad huh?
If you don’t want the hassle brought by software and application, think of browser extensions. These scrapers operate in your web browser and it simplifies the extracting process with just ticking the addon toggle. There are many different extensions in this area, and let’s look at one representative.
Webscraper.io
Like most no-coding required softwares, it offers a point and click interface that makes it easy-to-use for ecommerce store operators. Even as an extension, it can realize features of some large software such as multiple levels of navigation and JavaScript execution. The former enables us to get more detailed information of a listing or subject by navigating to its subcategories and the latter increases the success rate of scraping Javascript based pages, which are harder to scrape than HTML based page as they can modify the content based on user interactions or data received from a server. For an extension, that’s cool. And it also supports cloud automation in paid plan. But compared to software, they are less stable and can only consume a limited amount of data.
Coding Required Scrapers
Web scraping APIs are the representative of this kind. Popular scraping APIs include ScrapingBee, Diffbot and Zyte. They can be embedded directly into custom applications and automate extraction tasks within existing workflows or systems, which provide more convenience for developers.
If you’re not sure whether to adopt an API solution, consider the following subfactors:
Programming Background
If you possess programming knowledge or have developers to do the setup and maintenance, APIs will be easier for you.
Need for Real-time Data
For SMBs that need real-time data for their operations such as dynamic pricing, APIs will be a suitable solution as they can provide the latest data directly to the systems without manual intervention.
Large-scale Operations
Enterprises or users needing to scale their data extraction tasks across many web pages or websites might find APIs more efficient because they are built to handle large volumes of requests and can manage the load balancing, retries, and network/blocking issues more effectively than desktop-based software.
Integration Need
Using APIs can avoid the hassle of exporting data from software and then importing it into database such as CRM systems.
Automated System
Systems that operate with minimal human oversight, such as automated content monitoring systems, might use APIs to streamline processes and ensure efficient operation without frequent manual updates or checks.
ScrapingBee
Modern websites become harder to scrap as they tend to use Javascript and other technologies to load content dynamically. Compared to traditional static HTML based webpages where you can get all the information directly, JavaScript-based pages only present the information to users when interaction happens. In this case, traditional scraping gets harder as it will miss dynamically loaded information during the process.
A headless browser, however, can interpret JavaScript just like a regular browser, ensuring all content is loaded before scraping it. But these headless browers are sometimes too complex to maintain and time consuming. That’s why ScrapingBee comes into place and take the heavy lifting over so developers who don’t want to deal with the complexity of JavaScript rendering can focus more on the main target, which is extracting the data they need.
What is a headless brower and why it is important in data scraping? A headless browser is a web browser without a graphical user interface(GUI). This means it doesn’t display web pages visually as standard browsers like Google Chrome do. Instead, a headless browser runs in the background, executing web pages as if it were a real browser but without any visible output. Headless browsers can dynamically interact with web pages, navigating websites and extracting large amounts of data without manual intervention. This makes them a perfect solution for scraping data from sites that load content dynamically with JavaScript. Except for headless instances, they can handle proxy rotation to help developers bypass rate limiting. Another way to avoid blocking issues.

Zyte
Similar to ScrapingBee, Zyte offers ban handling for their scraping API. Key services include automated proxies rotation and residential proxies to lower the possibility of being blocked and banned. They also handle headless browser & rendering to lessen developer’s burden.
Diffbot
As a natural language analysis product, page data crawling is just the first step for later analysis, such as sentiment analysis and knowledge graph building. In the scraping part, they offer data extraction in fields of news & articles, organization, products, events and discussions for better and more thorough marketing intelligence.
And its automatic extraction API enables users to either “extract” some targeted data from a specific url or “crawl” a much larger number of pages or sites. The former is more suitable for tasks like extracting product information from e-commerce sites, pulling article content for a content aggregator, or obtaining contact information from business directories, while the latter is ideal for projects requiring extensive data collection from various sources, such as market research, competitive analysis, and building large datasets for AI training or content aggregation.
DIY Scrapers
For developers who want to build their own scraper, as this will give them more freedom by choosing the language they prefer as well as building infrastructure, Scrapy or Beautiful Soup is a good go-to place. Though they are all python web scraping tools, Beautiful Soup is about parsing library while Scrapy is a comprehensive web scraping framework.
The difference between Library and Framework:
A library is like a set of tools that developers use on their terms, pulling various functions as needed without any change to how they manage their project. It offers specific functionalities and is quite passive.
On the other hand, a framework provides the main structure for a project. It tells you how the entire application should be built and managed. It’s like a blueprint that you need to follow closely, making it more directive and controlling than a library.
If your projects are complex then Scrapy might be the option as it performs better in terms of speed and efficiency. While Beautiful Soup is more suitable for simple needs.
One-stop Solution: Database
If you have a bigger budget, a database would save you all the learning, maintaining and debugging process. Octoparse provides customized service from which you can get a tailored crawler for your extraction.
Tools Comparison Table
If you are still confused and hesitate which to choose, here’s a comparison table for deeper digest.
| Octoparse | Screaming Frog | SrapeBox | Waterscraper.io | |
| Coding Required | ❌ | ❌ | ❌ | ❌ |
| Areas | Any | SEO | SEO, Youtube | Any |
| API Access | ✅ Available in paid versions | ❌ | ❌ | ✅ |
| Data Volume | Scalable with cloud based option | Scalable | large | Scalable |
| Recurrence | ✅ | ✅ | ✅ | ✅ |
| Maintenance | ✅ | ✅ | ❌ | ✅ |
| Free plan | ✅ | ✅ | ❌ | ✅ |
| Unblocking technologies | IP rotation, CAPTCHAs solving, Proxies, dynamic website handling | – | Includes proxy support and advanced scraping features. | IP rotation |
| Data Output | CSV, Excel, JSON, HTML, XML, Database(Google sheet, MySql, SqlServer) | CSV, Excel, or directly to Google Sheets. | CSV, direct database integration | CSV, XLSX, JSON, Dropbox, Google Sheets, Google Drive or Amazon S3 |
| Dataset | Customized Crawler | Custom extraction using CSS Path, XPath, and regex supported. | Extensive customization options using built-in tools and additional plugins. | ❌ |
| ScrapingBee | Diffbot | Zyte | Scrapy | Beautiful Soup | |
| Coding Required | ✅ | ❌AI powered | ✅ | ✅Python Framework | ✅Python Library |
| Areas | Any | NL, Knowledge Graph | Any | Any | Any |
| API Access | ✅ | ✅ | ✅ | ❌ | ❌ |
| Data Volume | Scalable | Scalable | Large | Large | smaller |
| Recurrence | ✅ | ✅ | ✅ | ✅Can be programmed for regular scraping. | ❌Not built-in; requires additional scheduling code. |
| Maintenance | ✅ | ✅ | ✅ | ❌Requires developer skills for maintenance. | ❌Developer maintenance needed. |
| Free plan | ✅ | ❌ | ✅ | Free(open source) | Free(open source) |
| Unblocking technologies | automatic proxy rotation and headless browser capabilities | Advanced AI and machine learning to navigate complex sites. | smart proxy management. | Supports various middleware for proxy and user-agent rotation. | ❌Needs combination with other tools like Requests. |
| Data Output | HTML, JSON, and CSV | JSON, CSV, Excel, and more. | JSON, CSV and more | JSON, XML, CSV. | Depends |
| Dataset | customized data extraction setups | AI-driven customization and entity extraction. | Extensive customization options available. | Highly customizable through coding. | Customizable with Python coding. |
Hopefully, this article answers the questions in your mind and helps you choose the solution that best suits your cases. If you have any other questions, do feel free to contact Octoparse. We are here to help every step of the way during your scraping journey.




