It may once confuse you what is the difference between web crawler and web scraper as both of them seem to perform a similar action, which is extracting information from a web page. While that is the case, they are used in different areas. Fear not, if you are a tech novice. By reading this article below, you will get a thorough understanding of what they are and how they work.
Main Difference
Although these two bots may seem to collect information from websites, web crawlers tend to crawl a larger amount of pages and content as long as they are new and updated for Search Engines such as Google. Their mission focuses on the action “search”. While web scrapers are usually tools used to not only search desired information, but most importantly scrape them off and output them in structured data for later analysis.
| Web Crawling | Web Scraping | |
| Purpose | For visibility on Search Engine | Data Analysis in all industry |
| Mission | Search for new pages and updated content | Find desired content from specific url(s) and scrape them off |
| Application | SEO | Marketing, finance, lead, life, education, social media, consulting… |
Though web crawler is mainly related to SEO, it is sometimes interchangeable to mean web scraper. If you are not sure, use web scraper if you want to find tools to simplify your data extraction.

Having outlined the fundamental distinctions between web crawling and web scraping, let’s dive deeper into the principles and application of each process. This will help us understand not only how they differ in functionality and purpose but also how they are applied in various fields.
Web Crawler And Its SEO Significance
Web crawler, or spider, is a bot used by search engines to find new web pages or updated content in a known/indexed web page. It is highly important in the field of SEO as if your pages are not crawled by these crawlers, they cannot be indexed by search engines like Google. And there is no way audience can see your page even if they search a whole paragraph copied from your original text!
How Does A Web Crawler Work?
If the above is a bit difficult for you, think of the web crawler as a librarian. And the world wide web is the library where millions of books are stored. Here books are referred to web pages. There are new books coming in every day just like there are new web pages being created every minute. And the job of librarians, is to find those new books and categorize them by finding out what they are about, like book name, author, description, content, etc. And what web crawlers need to do is to find new pages and download their content. After that, the crawled pages will be stored waiting for indexing according to the category they fall into.
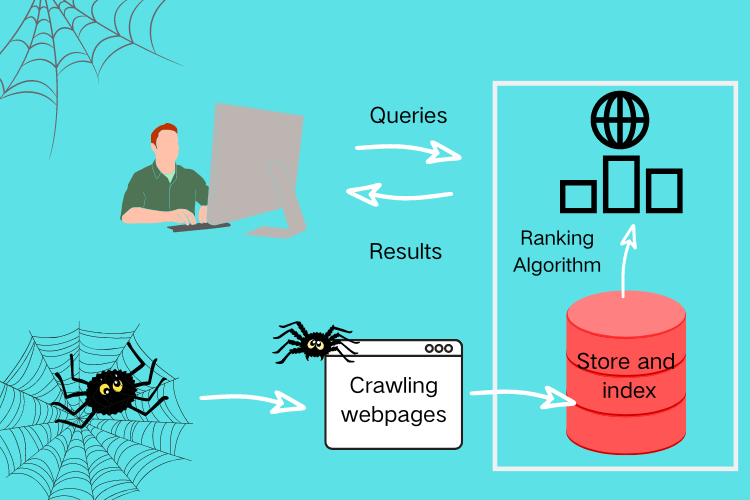
Example of a Web Crawler in SEO
Not only can search engines use crawlers to crawl pages, we can also use some website crawler tools to improve our SEO ranking visibility and achieve potentially higher conversions.
These tools are invaluable for identifying common SEO issues such as broken links, duplicate content, and missing page titles, which are crucial for optimizing your site. With a variety of web crawler tools available, it’s possible to select one that best fits your needs. These tools not only crawl data from website URLs but also help in restructuring your website to make it more comprehensible to search engines, thus improving your site’s ranking.
Below are some of top web crawlers. Each known for its unique features and capabilities:
Semrush
One powerful tool is Semrush, which goes beyond basic crawling functionalities to provide a comprehensive analysis of page structure, helping to identify technical SEO issues and enhance search performance. Semrush supports a wide range of SEO tasks, including keyword research, competitive analysis, and much more. It’s especially valuable for those who need in-depth insights into their SEO strategy and the competitive landscape.
Screaming Frog
Another prominent example of a web crawler tool is Screaming Frog. This tool is designed to crawl website URLs to help webmasters analyze and audit their site’s SEO in real-time. It can quickly identify broken links, analyze page titles and metadata, and even generate XML sitemaps. This kind of comprehensive crawling capability is essential for maintaining an up-to-date, SEO-friendly website.
By integrating these tools into your SEO strategy, you can ensure your website remains visible and competitive in the increasingly crowded digital landscape.
Web Scraping, A Great Smart Helper
If a web crawler extracts data from a large database like the world wide web (WWW) then web scraper focuses on a much smaller area for example, a specific website(url), or a batch of websites. And the purpose of web scraper is for personal or business usage.
Why You Need it
Today we are all swamped by seemingly countless information. And data analysis (including cleaning and processing) becomes ever more imperative to the point that even a bit of information can decide a company’s fate. In such cases, how to gather information quickly and efficiently for market research becomes a skill one needs to survive in this information competing era.
And web scraper, usually a pragram written by python or a software, can help us extract desired unstructured data from designated areas of a webpage, and then transform them into organized or predefined struture in excel or CSV. For example, as an ecommerce shop owner, price monitoring is essential to keep one’s own price edge. However, copy and paste prices into your database from different shops is time consuming and makes people grumpy. Not to mention there will be duplicate content! Using a web scraper can beat the headache. You can write the code script and the scraper will help you do the job. No knowledge of programming knowledge? Check Octoparse, a free no-coding solution!
How Does A Web Scraper Work?
All our web pages are structured in HTML and what web scapers do is to parse the HTML in the page and locate the designated area that stores your desired data. After it finds the location, it will start to scrape the data and output them in a format that you prefer. Most importantly, this automated process can be set to repeat at an interval!
Types of Scrapers
There are two types of scrapers. One is self-built, written in code, usually python. The other is pre-built scraper such as software, or browser extension.
Writing your own code may be time consuming and it poses a hurdle for those no-coders. While there are software scrapers that help you with python libraries, no-coding-required softwares present a much enticing solution!
No-coding Software
Take Octoparse for example.
It simulates the process of human beings extracting data in the page by pointing and clicking. All you need is just a targeted url, and Octoparse will auto-detect the data area for you to choose from. Of course, you can choose yourself within a few simple clicks. Then an automated workflow will be created for you signaling the sequence of the steps one needs to take to copy and paste data. Simple, right?
Software scrapers also have more advanced options than self-built scrapers and extensions. For example, Cloud Run feature. This is the greatest thing that has happened to SME who focuses on efficiency. Cloud run means all your scraping projects can be run on the cloud servers instead of your local server. And meanwhile, your local server can focus on other tasks.
APIs
For those who don’t want to spend extra time on building and testing, APIs(application programming interfaces)will be a better option. Now many large websites such as Google, hubspot, Facebook, ChatGPT, offer APIs that allow you to access their data in a structured format. And normally API will be more stable in data collection as it is consumed by programs rather than by human eyes. Even if the front end presentation of a website changes, its API structure remains unchanged, which makes API a more reliable source of data.
How Web Scraper Fuels Your Business?
- Price Monitoring
Price competitiveness accounts for a large part in product sale and that’s why price monitoring becomes essential for ecommence shops to gain an edge in this cut-throat competition. Instead of copying and pasting prices of different products from different sources, shop owners can now use scraping tools to get that information not just within minutes but also avoid wrong or duplicate content caused by human eyes! With the data at hand, shop owners can also adjust inventory based on market trends such as demand and supply and avoid possible risk of unnecessary product hoarding.
The Internet is growing at exponential speed and there is no doubt these vast amount of information, over 1.9 billion websites, which will still be growing, contain as many valueable insights as our brain can reach. For any start-ups who want to enter a new business or industry, existing product offerings, specs and marketing share will help them notice a wiser niche to explore. And for those growing companies, consumer behavior and preferences analysis make sure that their products always align with the market needs.
Lead collection will be a time-consuming headache for B2B companies. Especially when the sources are scattered in different platforms. With scraping tools, even companies that don’t have developers can fasten this gathering process and focus more on what they actually excel at.
With scraper, real estate agents can compare the price of properties across different platforms and even build from scratch a comprehensive database of properties listing. Buyers can also gain knowledge of a property’s neighborhood by extracting information about schools, facilities, crime rates and hospitals before taking an action. More details about the property like floors, parking spaces and room size can also be collected. For investors, they can make a wiser investment based on the evaluation of past data on price change and purchase trends.
Essay writing normally entails large amounts of data for experiment or context analysis. And web scrapers can help students collect statistical data online to support trend analysis and effectiveness of certain practices. Except for past data, scholars are also able to track and gather real-time data to ensure data freshness by setting a project that runs periodically.
For businesses where current events significantly impact operations, web scraping provides a means to monitor news outlets and social media platforms continuously. This real-time information can be vital for crisis management, public relations, and staying informed about industry developments. Financial institutions, for example, may use web scraping to track news that could affect stock prices or market conditions.
Web scraping is instrumental in sentiment analysis, where companies assess public opinion about their brand, products, or services through data collected from social media and review sites. This analysis helps in product improvement, customer service enhancement, and effective marketing. For example, a tech company might scrape online forums and tech blogs to gauge consumer reactions to a new product launch.
These examples underscore the importance of web scraping in providing actionable insights and supporting strategic decisions across various sectors. Yet there are still many other possibilities for you to explore.
Kind Reminder
You can choose what suits you at the present moment, but do check the terms of service of the website you are going to scrape before action to avoid any rule violation.
Tips for Action
If you are a no-coder or developer who wants to save some effort, no coding software is your perfect go-to solution. It can save you the headache of script writing and do all the necessary jobs for you, such as IP rotation, ready-to-use template, duplicate content removed, cloud run, etc. Check Octoparse for all the features mentioned above by starting a free journey!




