About Craigslist
You must have heard of Craigslist, which is known as a well-rounded classified advertisements website with sections of various post categories. Sometimes, we may want to scrape data for various reasons of research analysis, commercial prediction, personal uses and some other intentions. However, scraping or crawling data from Craigslist is truly a bit challenging when considering how to set up everything for their website. Craigslist doesn’t provide any public APIs for users to scrape data and have data formatted compared with most other websites and databases, like Facebook, Twitter, Amazon, etc.
Why Craigslist Blocks
As we mentioned before, Crigslist should be categorized as a special site for its different structural architecture. They do have an API, while it only allows you to post but not to pull out read-only data, which is essentially different from other sites. This scheme and implementation may embarrass some people, however, it does benefit Craigslist by denying amount of crawlers and scrapers’access to their dataset from the view of Craigslist themselves. This implies that you may only visit Craigslist via a web browser or email client, post to Craigslist or their bulk posting API, nevertheless, any intention to scrape or crawl their dataset concerning personal or contact information will be banned.
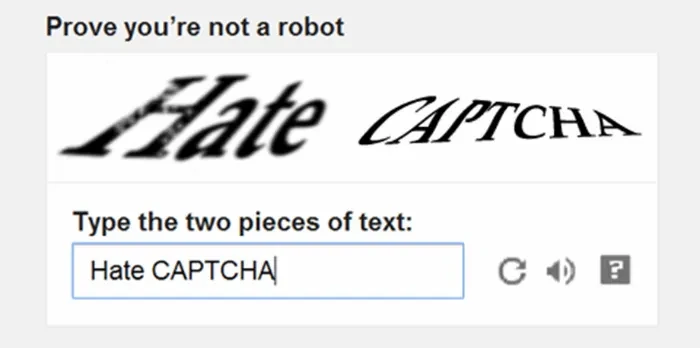
Here, the concept of scraping legality should be mentioned, since Craigslist has even taken legal measures to deal with those with detrimental scraping or crawling based on the data scraping scale, how and where the data is used. It also uses the CAPTCHA service from Google to help verify that a real person is posting an ad. Therefore, it implies that it would be hard for people to collect data and bypass CAPTCHA intellectually.
How to solve Craigslist Captcha
- Proxies for browsing Craigslist
Since we know Craigslist is aggressive about scrapers with its particular CAPTCHA and API schemes, proxies should be considered as an option. Why? Their only way to identify a scraper is to sense the same IP address by keeping sending requests to the webpage too frequently. It is not able to tell what users are doing, it just browses, like the crawler or spider. Talking about the proxies, they lessen the traffic by utilizing a list of rotating web servers, tunneling the origin from the website. We may then select certain scraper tools to process the IP rotation.
- Tools that can bypass Craigslist captcha
There are some easy-to-use automatic scraper tools we can choose from so that we can deal with these configurations in a much more effective and easy way, like Octoparse, Import.io, Unipath, etc. These tools all provide more succinct methods for us to configure the rotating proxies, even though they have provided a more reliable Cloud-based Service. Anyway, even though we could deal with the dilemma caused by Craigslist particular API scheme, there still exists a problem given by Craigslist CAPTCHA. Until now, few scraper tools could wrestle with such complex tasks concerning CAPTCHA. Thus, a more practical and prevalent approach taken now is to utilize CAPTCHA Human Bypass, which implies it requires some labor work. Anyway, bypassing the CAPTCHA may not be that far away, as people have achieved this “bypass” action by looping through the images from CAPTCHA until OCR readable ones are retrieved. Then, the final result is that thousands of CAPTCHA images are retrieved. All in all, for the CAPTCHA Bypass while scraping, we still have a long way to go.