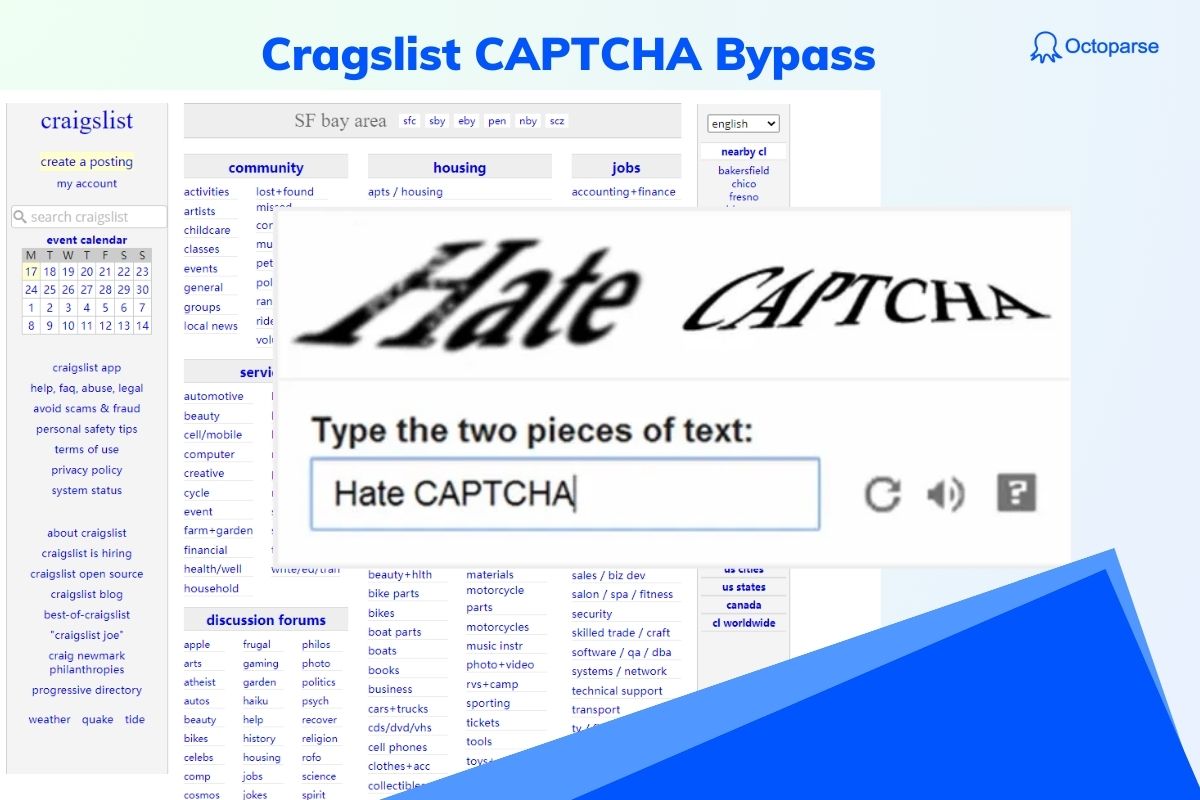
reCAPTCHA is one of the most common security measures used by websites to prevent automated bots from accessing their content. Developed by Google, it is designed to differentiate between human users and automated scripts, making it a significant challenge for web scrapers and automation tools.
For businesses and researchers who rely on web scraping for data collection, encountering reCAPTCHA can be a frustrating obstacle. While its primary purpose is to prevent malicious bots, even ethical data extraction can be disrupted. In this guide, we’ll explore different 4 types of reCAPTCHA, the legal implications, and provide practical methods to bypass reCAPTCHA effectively and responsibly while web scraping.
4 Different Types of reCAPTCHA
Before discussing how to bypass reCAPTCHA, it’s important to understand its various versions and how they work.
1. reCAPTCHA v2 (“I’m not a robot” Checkbox)
This is the most commonly encountered CAPTCHA, where users must click a checkbox labeled “I’m not a robot.” If Google suspects bot activity, it presents an additional image-based CAPTCHA test.
How it works:
- It tracks user behavior (mouse movement, clicks, session history).
- If suspicious, it presents challenges like selecting objects in images.
2. reCAPTCHA v2 Invisible
Unlike the checkbox version, Invisible reCAPTCHA v2 does not require user interaction unless suspicious activity is detected.
How it works:
- Google analyzes user interactions on the website.
- If it detects bot behavior, it triggers an image-based CAPTCHA.
3. reCAPTCHA v3 (Score-Based CAPTCHA)
This version does not interrupt users with challenges but instead assigns a score (0.0 – 1.0) based on how likely a request is from a bot.
How it works:
- Websites set a score threshold; low-scoring users may be blocked.
- Google evaluates user behavior, device fingerprinting, and browsing history.
4. reCAPTCHA Enterprise
This is a more advanced version, primarily for high-security applications like banking or sensitive accounts.
How it works:
- It uses AI-powered risk analysis to determine bot activity.
- Websites get customized security settings based on their needs.
Each of these types presents different challenges for web scrapers. However, there are ways to bypass reCAPTCHA effectively and legally.
Is It Legal to Skip reCAPTCHA
Bypassing reCAPTCHA is a gray area in legal and ethical terms. While it is not outright illegal, violating a website’s terms of service (TOS) can lead to restrictions, bans, or even legal action. Here’s what you need to consider:
Situations Where It Is Acceptable
- Scraping publicly available data that is not behind a login.
- Using an API if the website provides one instead of scraping.
- For academic, research, or compliance purposes where data collection is necessary.
Situations Where It Can Be Risky
- Bypassing reCAPTCHA to access private data or log into accounts you don’t own.
- Using scraping for spam, fraud, or malicious purposes (this can lead to legal consequences).
- Scraping against a website’s TOS (websites may issue bans or IP blocks).
It’s Best to Do
- Check the website’s robots.txt file to see if scraping is allowed.
- Respect scraping limits by not overloading the server.
- Use ethical scraping tools that follow responsible data extraction practices.
2 Methods to Bypass reCAPTCHA
Method 1: Using Octoparse for Web Scraping (no coding)
Octoparse is an easy-to-use web scraping tool. It can help you to scrape website data automatically without any coding. Octoparse provides the cloud-based scraping feature which allows you to bypass CAPTCHA, including reCAPTCHA v2, with minimal effort. Since it runs scraping tasks in the cloud, it avoids many CAPTCHA triggers that occur when scraping from local devices.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
How to solve reCAPTCHA in Octoparse manually
Octoparse provides a built-in CAPTCHA-solving feature, which can handle simple CAPTCHAs easily during your data extraction. Follow the simple steps below, or move to the tutorial to learn more details about solving CAPTCHA.
Step 1: Create a scraping workflow
Use the auto-detection function of Octoparse to create a scraping workflow after you install Octoparse on your device. Just copy and paste the target website URL to Octoparse panel and click on the Start.
Step 2: Set CAPTCHA bypassing
After building the workflow, click on the Add Step button in the workflow, and select the Solve CAPTCHA option.
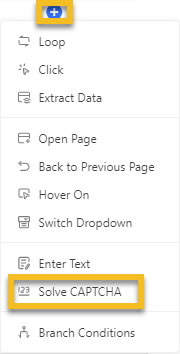
Select the CAPTCHA type as reCAPTCHA, and click Apply to save the settings.
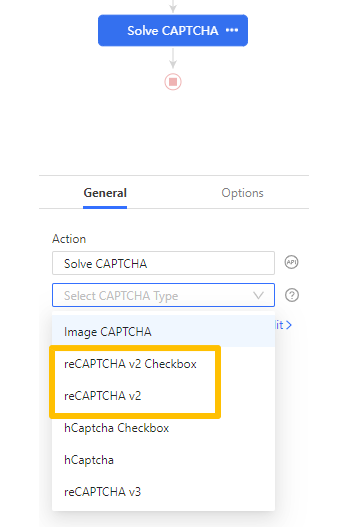
If the CAPTCHA you encounter includes a submit button, you can choose the reCaptcha V2 Checkbox, and click on a submit button which can direct you to the target page.
Next, choose the Click element/Click button to continue.
ReCaptcha won’t be resolved automatically until an actual data run. Thus, you need to turn on Browse Mode and resolve it manually to proceed when creating the task.
Step 3. Extract data without limit
Finally, check all your data extraction settings. Click on the Run button to start data scraping. You can download the data as an Excel file or other formats as you like.
Method 2: Using Browser Automation and AI-Based Solutions
Another effective method is using browser automation tools like Selenium, Puppeteer, or Playwright. These tools can mimic human behavior to reduce the likelihood of triggering reCAPTCHA.
How It Works:
- Selenium & Puppeteer: Automate interactions like scrolling, clicking, and entering text.
- AI-Based CAPTCHA Solvers: Use machine learning to recognize CAPTCHA patterns.
- Headless Browsers: Simulate real browsers but may increase detection risks.
Steps to Reduce CAPTCHA Detection with Browser Automation
- Use “undetected_chromedriver”: A modified Chrome driver that avoids easy bot detection.
- Add random delays and mouse movements: Mimic human-like browsing.
- Use real user agents: Ensure the scraper looks like a real browser.
While these methods can work, they require technical knowledge and may not be as reliable as cloud-based solutions like Octoparse.
6 Tips to Reduce the Frequency of reCAPTCHA While Scraping
Instead of bypassing reCAPTCHA, the smarter approach is to avoid triggering it. Here are some tips to reduce the frequency.
1. Slow Down Your Requests: Sending too many requests in a short time raises red flags. Add random delays between requests to mimic human behavior.
2. Use Proxies & Rotate IPs: Use residential or mobile proxies instead of datacenter proxies. Rotate proxies to avoid detection and prevent IP bans.
3. Mimic Human Behavior: Bots move predictably, real users don’t. Randomize scrolling, mouse movements, and clicks using Selenium. Vary navigation paths and use different referrers to seem organic.
4. Rotate User-Agents & Headers: Use real browser headers and rotate user-agents to avoid bot detection.
5. Maintain Sessions: Avoid starting a new session on every request; use persistent cookies.
6. Scrape During Off-Peak Hours: Scraping at night or early morning reduces the risk of detection as website traffic is lower.
Here are more tips for you to get smoother while web scraping, move to read the article: 9 Tips for Web Crawling Without Getting Blocked
Final Words
Bypassing reCAPTCHA is a challenge for web scrapers, but using the right tools and techniques can help reduce detection and automate CAPTCHA-solving.
- For non-technical users, Octoparse provides a built-in CAPTCHA-solving feature and supports third-party CAPTCHA-solving services.
- For developers, browser automation tools like Selenium and AI-based solutions can be used.
While bypassing CAPTCHA is possible, ethical scraping practices should always be followed to avoid violating a website’s terms of service. By implementing these strategies, you can ensure efficient and responsible web scraping while minimizing CAPTCHA-related disruptions.