XPath expressions help you easily navigate XML/HTML documents. As you may notice, web scraping is all about parsing through HTML documents. In this regard, XPath is quite handy in web scraping projects as it enables you to programmatically access HTML elements, locate data, and extract useful data. CSS selectors are one of the XPath alternatives, but XPaths are far more versatile than CSS selectors when it comes to navigating the DOM (document object model). Read this insight to understand:
- XPath in detail,
- Its significance in the web scraping world,
- How to find XPath if you’ve no prior knowledge of XPath,
- A few basics of XPath, so that you can write your own.
Let’s get started.
What is XPath?
XPath stands for XML path language. Visually, it looks like a URI. From a conceptual angle, it is very similar to real-world navigational instructions. Ever found yourself globetrotting from one location to another on Google or Apple Maps? If you have, you would know these apps instruct you to take left/right after XYZ meters. But how do people instruct when you don’t have access to Maps and don’t know the route either? Their instructions look like this: keep going straight and take the first left after Dominos. While the apps give you absolutely [take left after 200 meters] navigational paths, real people give you relative [take right after Zara store] navigational paths. XPaths too are of two types. Can you guess them? Yes, absolute XPaths and relative XPaths.
That was a casual introduction to XPath. In technical lingo, Xpath is a path language used to locate a node or nodes in an XML or an HTML file. It is not complicated like a programming language but has a set of grammatical rules to write paths that traverse the DOM to access certain content on the web page.
It is especially useful for web scraping. We use Xpath to locate data in web scraping. It’s a must-learn skill if you are extracting data from web pages. If you are getting data from websites with a tricky structure, Xpath knowledge can save your day! Nothing explains better than a hands-on experience. For demonstrating and helping you understand let’s analyze the DOM of Levi’s website.
You can open this in a browser of your choice: Chrome, Edge, Firefox, Safari, UC Browser, etcetera. Bring the “developer tools” on the screen. In Chrome, you can do this easily by pressing “Ctrl + Shift + i”, or by right-clicking your mouse and choosing to inspect the element.
Doing so will pop up a developer tools screen with “Elements” as the active tab. This tab shows you the source code for the active web page. You can move your cursor over the HTML tags and observe the highlighted sections on the webpage. Each of these tags can be considered a node and it can comprise zero to multiple child nodes. XPath is a syntax that helps us navigate through these HTML nodes.
Now, just for a demo – I’ll write an XPath to access these recommended jeans on Levi’s website. In Chrome, you can press the keys “CTRL + F” to fire up a search bar within the developer tools panel. Observe it at the bottom. In Firefox, it’s active by default at the top.
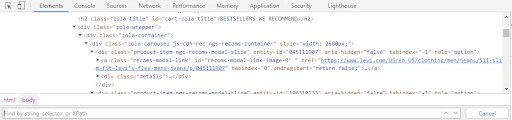
In this search bar, you can write and validate any XPath. Observe how the HTML node for the first recommended Jeans got highlighted when I wrote an XPath for it in the search bar. Hovering over the highlighted node also highlights the Jeans HTML component on the web page.
How XPath Helps in Web Scraping
Think of a scraper as your assistant. If you want him to buy you a pack of cereal, you have to explain where he can find it clearly so that he knows exactly where to grab it: which street, in which shop, and on which shelf. Xpath is the language that works as an address. For scraping HTML documents, XPath tells your scraper:
- What to scrape i.e, what data needs to be extracted, and
- From where to scrape i.e, which HTML Node will give that data?
Extending on our example above, if we need price data of the top 10 recommended products on Levi’s home page, we can write an XPath to help document parsers identify the HTML nodes containing prices. Here’s how it is done:
//div[contains(@class,”zola-carousel”)]//div[contains(@class,”price”)]
Challenges in locating data
- Say, you need to gather data across multiple pages, and the robot will repeat the same set of steps across pages to scrape the data. But the same element may be embedded in different structures on pages 1 and page 10. In this case, steps that work on page 1 may cause errors on page 10.
- The thing is, you don’t want to confuse the robot by offering a vague address where it encounters a lot of targets. Very likely he will grab the nearest one and it may not be the one you have expected.
So writing an XPath is sensible to give the unique address to a node that contains your target data. The robot can reach exactly the data of your interest and will extract highly consistent data. Relative XPaths written using the components that are less likely to change will work for a longer period and would need less maintenance. For example, I would prefer using contains[text(),”$”] over @class=”price” as identifiers, if both serve the purpose.
Why Should You Use XPath For Web Scraping?
I can nullify the following reasons to use XPaths for building robust web scrapers:
- Helps you reach any visible, or non-visible node, or a collection of nodes on a web page i.e., an XML document. In the above Levi’s example, we accessed 10 price nodes i.e., a collection using a single XPath.
- XPath expressions can be used in PHP, Python, Java, Javascript, C, and C++.
- It is a W3C norm and has 200 built-in functions to access numeric values, and boolean values, for comparing date and time values, and for node manipulation too.
- XPath can access 7 types of DOM components: HTML elements or nodes, attributes, namespaces, comments, text, processing instructions, and document nodes.
- Xpath can traverse a web page in any direction. It can also leverage the relationships between nodes to navigate the DOM i.e., you can write XPaths to find parents, siblings, Descendants, ancestors, etcetera of a node.
- Relative XPaths can be very effective even if the website structure changes.
- XPaths can start either from the root node i.e., / or it can start from any node //. You have functions like position(), last(), etcetera that you can append as predicate and use along with operators like <, >, <=, +, -, div, etcetera to selectively access/extract data from the web page.
Learn more about writing XPaths here.
Octoparse’s workarounds
Octoparse is committed to making Web Scraping easier, faster, and better, especially for non-coders. They can get web data just as programmers do.
- Auto-detection feature
Octoparse uses AI to intelligently detect useful data on the web page. The feature is called the auto-detect function and is available from Octoparse version 8 onwards. The auto-detect feature has been very successful and effective in detecting tables, infinite scrolls, loading more, listing data, and several other web design paradigms.
Steps to use Octoparse’s auto-detect feature for web scraping Amazon.com:
- Enter the URL on the home screen after logging into the Octoparse tool.
- Click on “Start” and then “auto-detect web page data”.
- Octoparse automatically detects data, labels it, and asks for your permission to create a workflow.
- Click on Create Workflow option in the Action Tips dialog. And BANG!!! The workflow is automatically created.
Easy-peasy! Is it not?
- Select by point and click in the built-in browser
Alternatively, if you’re using an older version of Octoparse, or if the new version 8 auto-detect function doesn’t work effectively for a website (rare case), then you can point your cursor to your target elements and choose an appropriate action in the action TIPS menu to extract the data. If you want to view or modify XPath, even that is possible.
>> More specific guides to find Xpath with Octoparse
How to find Xpath
If you are a total newbie and have no idea of terms like “node”, “element” and “attribute”, get yourself some basic knowledge in W3C HTML first. Here are some crash courses for XPath learning:
Find the right Xpath in Chrome
1. Copy Xpath in Chrome
Steps to find XPath in Chrome developer tool:
1) Fire up Chrome developer tools by inspecting an element in the DOM. You can do so by pointing your cursor to the target DOM element and then right-clicking on the target element. Next, you can select the Inspect element option from the pop-up menu.
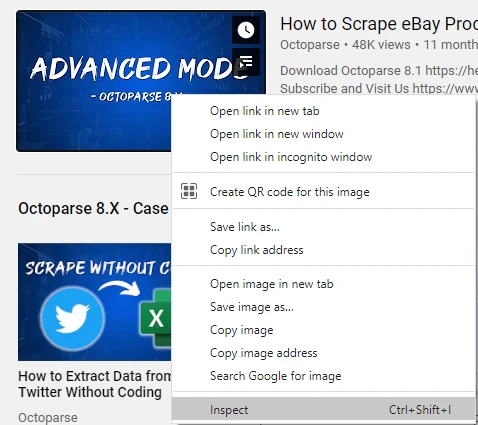
2) Now, again right-click on the HTML element of the target and copy the XPath. Easy!
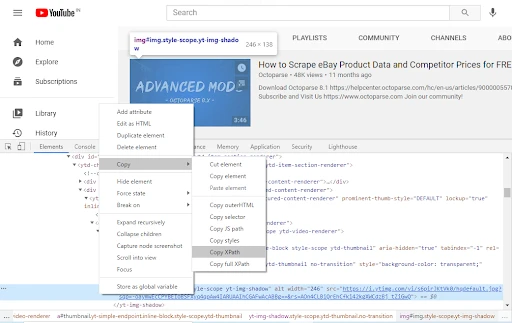
2. Write your own with Xpath Helper
You can also write your own XPath using the XPath Helper Chrome extension. Additionally, Octoparse also has an in-built XPath tool (available in Octoparse 7) to make things easier for you. To write your own XPath read this in-depth tutorial.
Conclusion
XPath is an integral part of any web scraping project. Tools like Octoparse make it easy for you to scrape the web by intelligently writing XPaths for you under the hood while you point and click at your target data. The new innovative auto-detect function of Octoparse eliminates the need to even point-&-click. For more resources on Scraping stay tuned to Octoparse on Twitter. Happy Scraping!




