Are you looking to scrape movie data from websites like IMDb, Flixster, and Rotten Tomatoes? I will introduce an easy-to-use movie scraper that you can gather all the on-page data without any coding skills.
What you can get with a movie scraper
This is a movie scraper that helps scrape data like:
- Movie name
- Year
- Category
- Ratings
- Introduction
- Cast
- Cover image (URL)
And you may scrape other data such as movie reviews, or TV show information as long as they are there on the web page. You can customize your scraper to get whatever data you want once you get a hang of it.
Getting Started
To help you fulfill data gathering, this article will lead you through a web scraping case to scrape the information from the IMDb movie list – IMDb Top 250 Movies.
We will start with the basic information: movie name, year, featured page URLs, cover image, and ratings.
(When you master the technique, you can use the advanced search to filter out the movies you are interested in and get the list of data all down.)
Prerequisites:
- Download Octoparse (Mac & Windows versions available, here is some instructions)
- Tatget URL (in this case: https://www.imdb.com/chart/top/?ref_=nv_mv_250)
Yes, we will be using this link to scrape the top 250 movies on IMDb:
https://www.imdb.com/chart/top/?ref_=nv_mv_250
Scraping Top 250 Movies in 30 Seconds
This is a step-by-step guide to scrape IMDb movie data with Octoparse auto-detection mode.
A quick view of the guide:
- Step 1: Open the target website in the Octoparse built-in browser.
- Step 2: Click the “Auto-detect web page data”.
- Step 3: Select the dataset you want to scrape and click “Create workflow” to confirm.
- Step 4: As the workflow is created, click “Run” to let it run.
- Step 5: Export the data for offline use.
Let’s dive right in!
Step 1: Open the target website in the Octoparse built-in browser.
On the Home page, simply enter the URL on the search bar and click “Enter”. The built-in browser will start to render the page.

Step 2: Click the “Auto-detect web page data”.
As the URL is successfully rendered in the Octoparse built-in browser, you will notice a yellow Tips Panel. There are options suggesting what you shall take for the next step.
At this point, click the option “Auto-detect web page data” and Octoparse will scan the page thoroughly.
Step 3: Select the wanted dataset and create a workflow.
As the auto-detection is finished, Octoparse will tell you what it has found out on the page that is very likely what you are looking for. And there may be more than one data result for selection.
Look down on the interface. What is the preview box now is the number one recommendation data result. Woohoo, this is a perfect form with the exact data we are looking to scrape.

If you want to switch to another result to check what Octoparse is offering you, click “Switch auto detect results” to meet your curiosity. Once you make your decision, click “Create workflow” to confirm your pick.
Step 4: As the workflow is created, click “Run” to let it run.
After clicking “Create workflow”, you will see some changes on the interface, and on your right side, there appears a so-called workflow of your movie scraper.
That’s about some commands and rules you set for the scraper to run. In this case, for auto-detection, Octoparse set it for you with its intelligent algorithm. You may learn how to build a workflow yourself in order to create a more customized scraper later.
Anyway, we have got what we want. And now we click on the upper right side the small little blue button “Run” to start the scraper. If you start free with Octoparse, choose to run on your local device.
Tips: Running in the cloud is faster and can avoid being blocked, click here to learn more about the advantages of cloud scraping.
I still got my data in 30 seconds. Web scraping is so amazing!
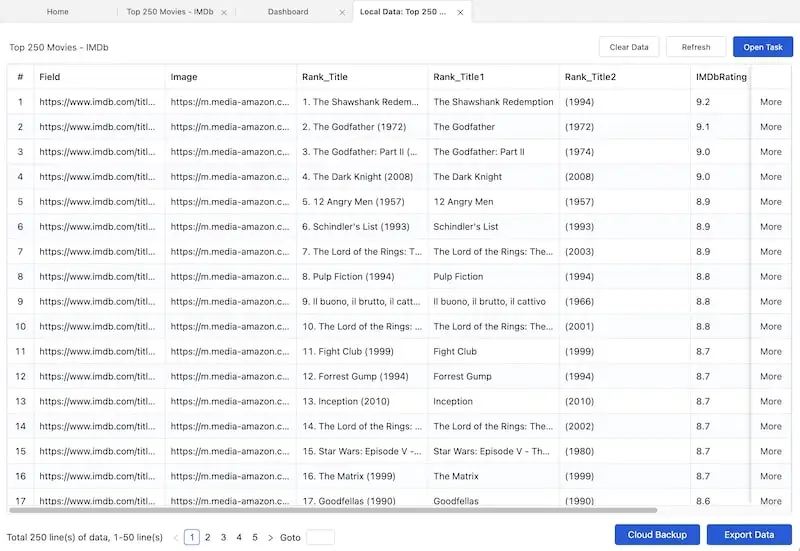
Step 5: Export the data for your offline use.
You must have witnessed how fast a web scraper can be to copy data from the web. As the data is well arranged and downloaded, you are available to export it in formats like Excel, CSV, HTML, or JSON.
We made it! The smart IMDb movie scraper. In the same manner, we can make a Flixster movie scraper, Rotten Tomatoes movie review scraper, and a Netflix TV series scraper, whatever you want.
Bonus: Preset template for IMDb data
With Octoparse, you can also get data from IMDb with their preset templates, which ask for only a few parameters, and you can finish the whole process online. Click on the online IMDb scraper below to preview the data sample and have a try!
https://www.octoparse.com/template/imdb-review-scraper
Final Words
With the above steps, I suppose, everyone, including those who have no programming background can easily build a movie crawler with Octoparse and get more than 100,000 lines of movie information. Besides, you can use the similar way to get book data from Goodreads.
Apart from the data, the more important is the skill you learned, which would be extremely useful if you want some data for market research, analysis, and many other things.




