Quickly export Google Maps search results to Excel—no coding needed. Learn simple, proven ways to scrape Google Maps business listings and build local lead lists fast.
Data mining has been the business game changer as who gets the information, who gets the edge. As a tool that helps fasten the data extraction process, web scraping software is bliss for any marketers or data analysts who want to draw insight from seemingly countless data.
Top 30 Web Scraping Tools
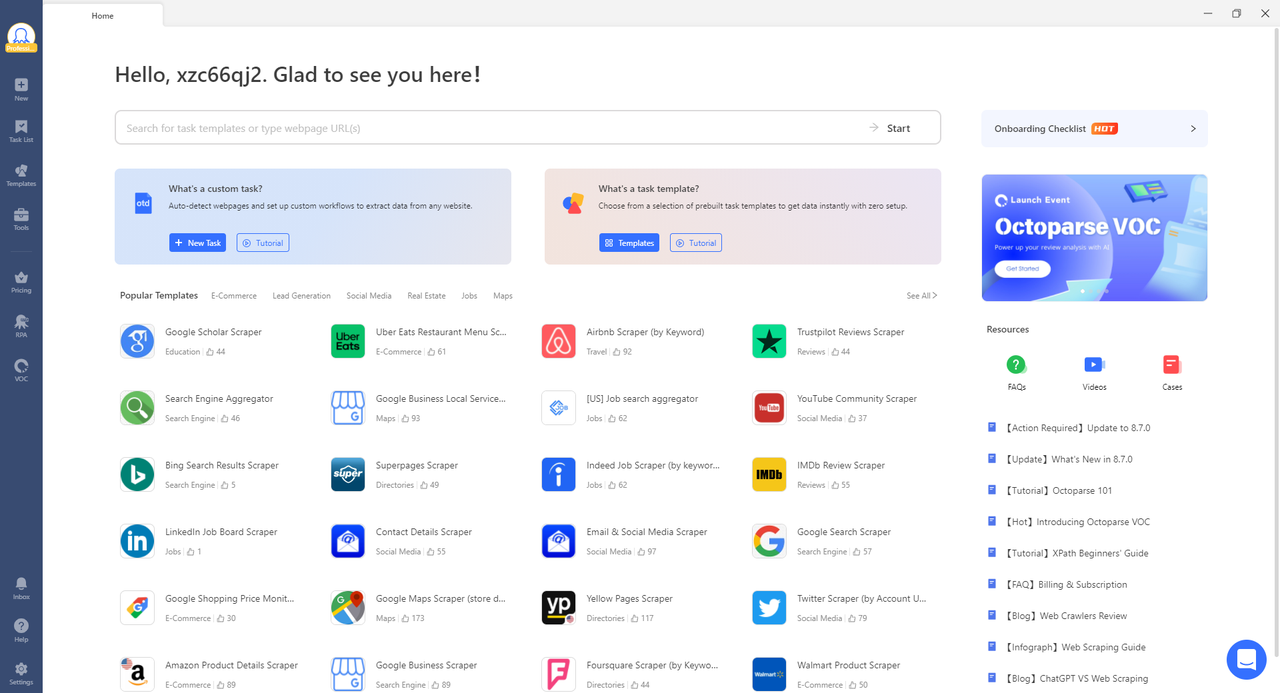
1. Octoparse – Recommended
Who is this for: Everyone without coding skills and needs to scrape web data at scale. This web scraping software is widely used among online sellers, marketers, researchers, and data analysts.
Why you should use it: Octoparse is a free-for-life SaaS web data platform. With its intuitive interface and auto-detecting function, you can scrape web data with points and clicks. It also provides ready-to-use scrapers to extract data from Amazon, eBay, Twitter, BestBuy, etc and is equipped with powerful anti-blocking techniques such as IP proxies, user agents, CATPCHAs solving, and log-in. If you are looking for a one-stop data solution, Octoparse also provides a data service. Or you can simply follow the Octoparse user guide to scrape website data easily for free.
Pros:
- Ready-to-use scrapers covering all popular websites; No code required.
- Custom scrapers service and data service.
- Anti-blocking settings: CAPTCHAs, IP rotation, User agents, intervals, and Log-in.
- Complex site handled: infinite scrolling, dropdown, hover, retry, AJAX loading.
- Cloud extraction and data storage.
- Free plan and 14-day free trial for Standard and Professional plans.
- Pay-as-you-go residential proxies; 99 Million+ IPs from 155 countries.
- Highly responsive support team: 24/7 via live chat in intercom
- Third-party app integration via Octoparse RPA; API access.
Cons:
- Not enough guidance for pre-built scrapers
Try Octoparse — the Easy-to-Use Web Scraping Tools Today:
2. Beautiful Soup
Who is this for: Developers and programmers, data scientists and analysts, and digital marketers who know basic programming.
Why you should use it: Beautiful Soup is an open-source Python library designed for web scraping purposes. It is used to parse HTML and XML documents and extract data from them. If you have programming skills, it works best when you combine this library with Python.
Pros
- Easy to use: has user-friendly API and simple syntax.
- Versatility: It can handle both HTML and XML documents, even poorly formed or invalid HTML.
- Flexibility: search and navigate the parse tree using tag names, attributes, and text. And easily modify the parse tree, enabling the cleaning and restructuring of data as needed.
- Compatibility with Other Libraries: Beautiful Soup works well with other Python libraries like
requestsfor fetching web pages andpandasfor data manipulation and analysis.
Cons
- Slower performance: when dealing with large documents or extensive scraping tasks.
- Limited Built-in Features: does not include capabilities for making HTTP requests; lacks advanced features like built-in support for handling cookies, sessions, and retry mechanisms.
- Steeper Learning Curve for Complex Tasks
3. Import.io
Who is this for: Enterprises needing large-scale data extraction for market intelligence. Or some eCommerce Companies who want to track product details, availability, and reviews.
Why you should use it: Import.io is a SaaS web data platform. It provides a web scraping solution that allows you to scrape data from websites and organize them into data sets. They can integrate web data into analytic tools for sales and marketing to gain insight.
Pros
- User-Friendly Interface: Easy to use with a no-code platform.
- Scalability: Capable of handling large-scale data extraction from numerous websites.
- Integration: Offers APIs and managed services for seamless integration with other tools and systems.
Cons
- Can be expensive, especially for small businesses or individual users.
- Long Learning Curve when you need to master all the features and functionalities
- Customization Limitations
4. Chat4Data
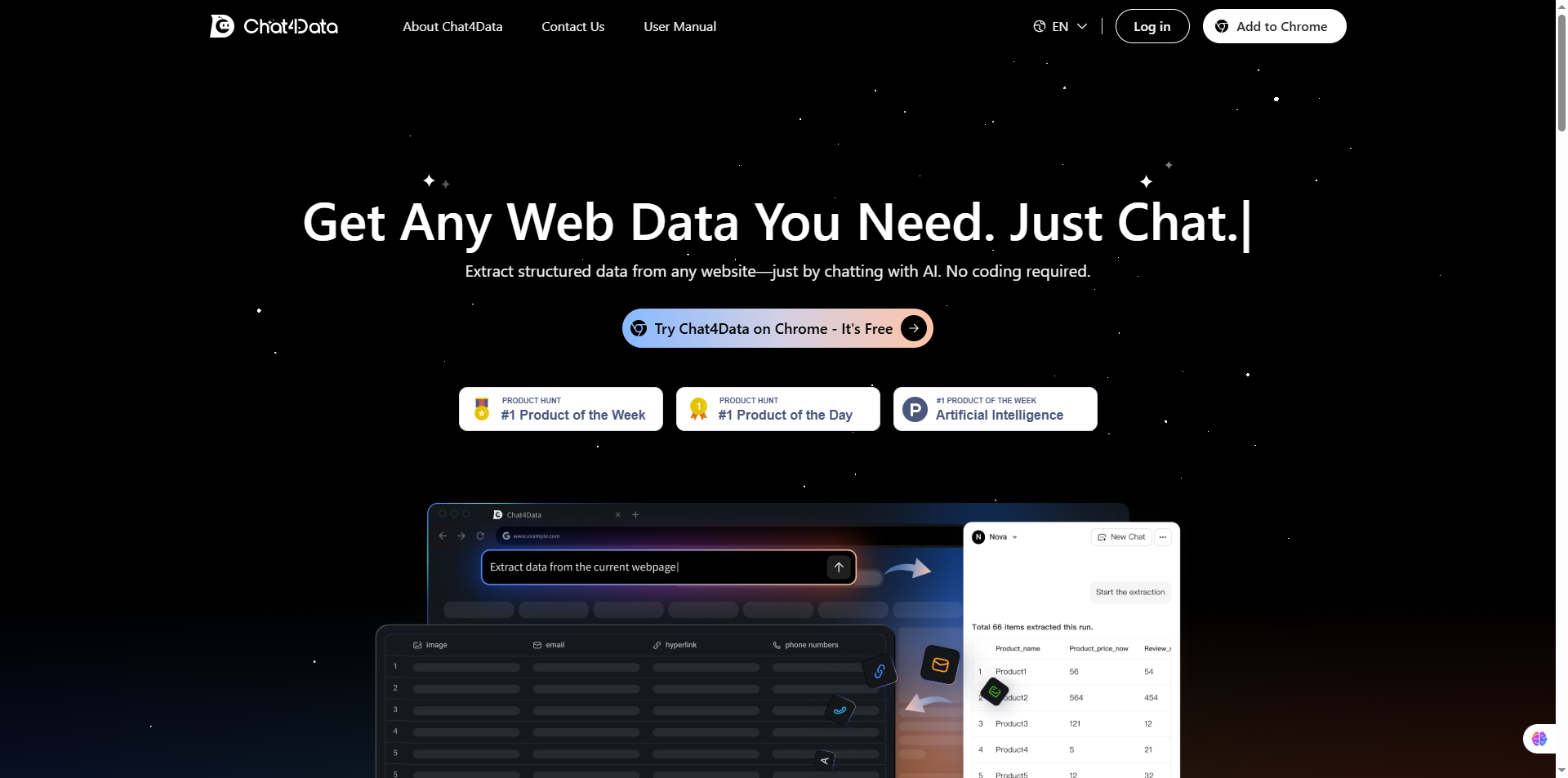
Who is this for: Individuals, small businesses, and e-commerce professionals who need fast, no-code web scraping for structured data from various websites. Ideal for those who prefer an AI-assisted, conversational approach rather than traditional coding-based scraping tools.
Why you should use it: Chat4Data leverages AI to make web scraping as simple as chatting. You can extract product listings, images, links, emails, phone numbers, and even hidden elements from any website without coding. Its natural language commands allow you to customize fields and automate pagination, making data collection faster, smarter, and more intuitive.
Pros
- No coding required: Simply chat with the AI to extract the data you need.
- Versatile data extraction: Supports most HTML websites, including complex e-commerce pages.
- Quick setup: Install the Chrome extension, sign up, and start scraping in three easy steps.
- Customizable fields: Easily add, remove, or adjust data fields via natural language.
- Automated pagination: AI handles multiple pages automatically for complete datasets.
- Affordable testing: Free 1 million tokens for new users; low-cost top-ups afterward.
Cons
- Limited file formats: Currently only supports Excel downloads.
- No historical session storage: Past scraping sessions aren’t saved, so you need to download data immediately.
- Chrome-only extension: Requires Google Chrome to use.
5. Parsehub
Who is this for: Data analysts, marketers, and researchers who lack programming skills.
Why you should use it: ParseHub is a visual web scraping tool to get data from the web. You can extract the data by clicking any fields on the website. It also has an IP rotation function that helps change your IP address when you encounter aggressive websites with anti-scraping techniques.
Pros:
- User-Friendly Interface: extract data with point and click.
- Flexible Data Selection: It allows for versatile data selection methods, including XPath, CSS selectors, and RegEx.
- Dynamic Content Handling: ParseHub can effectively scrape data from JavaScript and AJAX-heavy websites.
- Cloud-Based Execution
- Export formats: CSV, Excel, and JSON
Cons:
- Poor performance when dealing with large data or complex scraping projects.
- Limited Mobile Support: ParseHub does not have a dedicated mobile application.
6. Crawlmonster
Who is this for: SEO / SEM Professionals, Digital Marketing Professionals, UI / UX Professionals, Website Designers & Developers.
Why you should use it: CrawlMonster is a free web scraping tool for site audits and on-page SEO checks. It enables you to scan websites for any technical issues and analyze your website content, source code, page status, etc.
Pros
- Comprehensive Analytics: It offers powerful analytics tools for identifying and addressing technical issues on websites.
- Customizable Crawling: Users can set custom crawl schedules, adjust crawler speed, and define user agent strings to align with project objectives.
- Security Checks are supported.
Cons
- Potential Cost: Cost can scale up depending on features and scale.
- Limited User Feedback.
7. ProWebScraper
Who is this for: Companies, especially e-commerce; Data Analysts and Researchers.
Why you should use it: as another no-code web scraping tool, ProWebScraper can handle a wide range of websites, including those with dynamic content, thanks to its advanced features like XPath, CSS selectors, and regex. Besides, it can also set a schedule to run scraping tasks regularly.
Pros:
- Easy to use point-and-click interface.
- It has features like pagination, URL generators, XPath, CSS, and regex support.
- API supported.
Cons:
- Limited Free Version: The free version is restricted to 1000 queries.
- The basic plan offers data storage for only 15 days, which might be limiting for users who need long-term data retention.
- It needs the internet to run.
8. Common Crawl

Who is this for: Researchers, students, and professors.
Why you should use it: As a non-profit organization, Common Crawl offers a free and open repository of web crawl data. This data is widely used for various purposes, including research, analysis, and the development of applications involving large-scale web data.
Pros:
- Free and open to anyone;
- Extensive data: It boasts a dataset that spans over 250 billion web pages collected over 15 years, with 3-5 billion new pages added monthly.
- Common Crawl data has been cited in over 10,000 research papers.
- Community support such as Discord.
Cons:
- Complex data analysis: it requires advanced technical skills, particularly in big data processing and analysis to handle such a large pool of data.
- It needs enough storage and computational resources to process the data.
- Limited Granularity: While the data is extensive, it may not always provide the granular level of detail needed for specific use cases.
9. Crawly
Who is this for: People with basic data requirements.
What is it:
Crawly is a web crawler and scraper tool provided by Diffbot. It allows users to turn websites into structured data by crawling and extracting content like titles, text, HTML, comments, dates, entity tags, authors, images, and videos. The extracted data can be downloaded in CSV or JSON formats, making it useful for various data analysis tasks.
Pros:
- Easy to use: Put a URL and you can get all the structured data from a page.
Cons:
- Limited Control: While it simplifies the scraping process, it might offer less control compared to custom-built scrapers tailored to specific needs.
- It needs Internet connection to operate scraping tasks.
10. Content Grabber
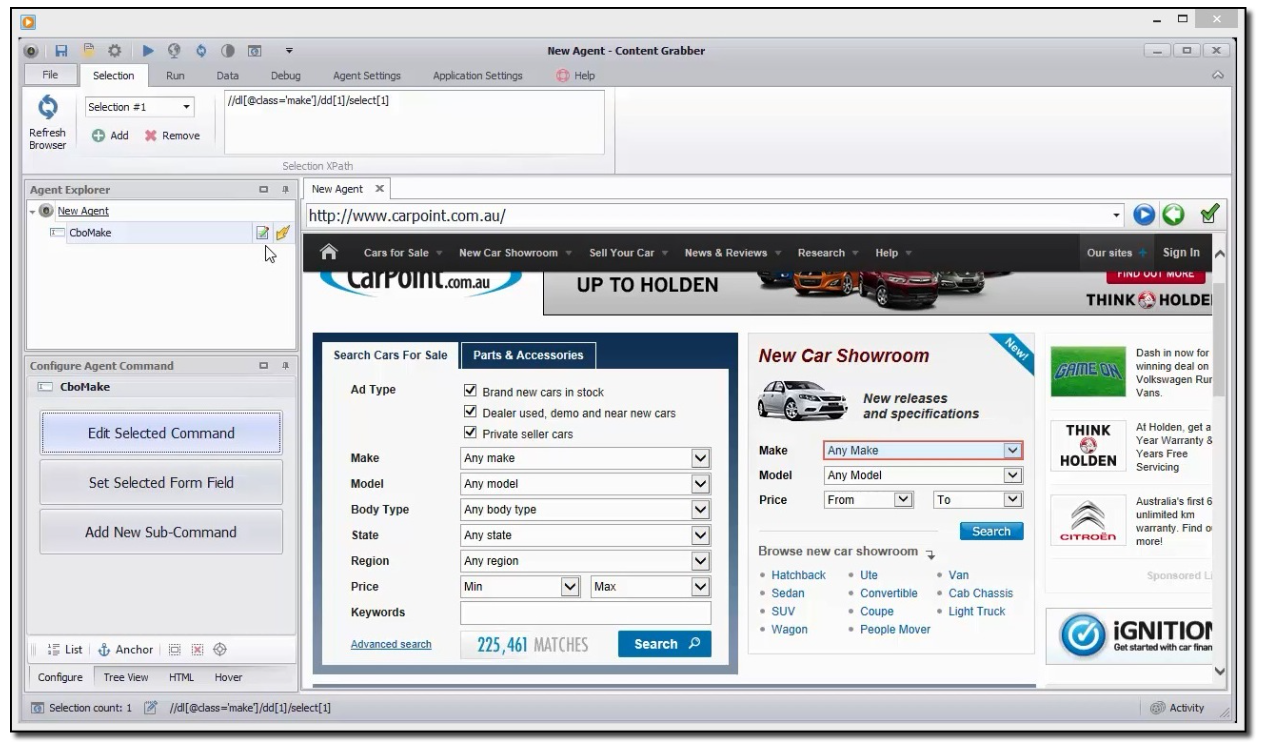
Who is this for: Anyone without much programming knowledge.
What it is:
Content Grabber offers a robust set of features, including a visual editor for creating scraping agents, automation capabilities, and advanced scripting options. It is particularly useful for those who need custom data extraction yet without extensive programming knowledge.
Pros:
- It has an easy to use and point and click interface.
- Advanced Features: It includes advanced debugging, logging, error handling, and custom scripting capabilities.
- Data can be exported in various formats such as CSV, Excel, XML, and databases.
- Complex site handling: It can scrape sites with JavaScript and AJAX.
Cons:
- Quite expensive: The starting price for an enterprise license is around $5,500 per year.
- Limited customer support.
- It doesn’t seem to be updating for a long time.
11. Diffbot
Who is this for: Developers and business.
What is it: By leveraging machine learning and computer vision algorithms, Diffbot can extract information and organize it into entities like articles, products, and organizations, which will later be updated through Diffbot’s Knowledge Graph for any potential business insights.
Pros:
- Can be integrated into different applications.
- Can handle large-scale web data extraction tasks.
- Continuously updates to the Knowledge Graph.
- Save time and energy building and maintaining web scraping systems from scratch.
Cons:
- Quite Expensive: starting at $299 per month.
- Limited Customization
- Occasional Instability
- Reaching customer support can sometimes take a little time.
12. Dexi.io
Who is this for: non-programmer
What is it: Dexi.io is a robust, cloud-based web scraping tool designed to help users extract and automate data collection from websites. It is particularly aimed at brands, retailers, and data-driven organizations looking to gain insights, optimize pricing, monitor product availability, and conduct comprehensive customer sentiment analysis. Dexi.io’s automation capabilities make it suitable for various complex data projects and integrations with other systems like MySQL, Amazon S3, and more.
Pros:
- It has a visual editor that is easy for non-programmers.
- Can integrate with multiple third-party tools and services.
- Can simulate human browsing behavior, handle CAPTCHAs, perform infinite scrolling, and execute JavaScript for more sophisticated scraping tasks
Cons:
- Complex for beginners.
- May not replicate all functionalities of common browsers like Chrome.
- Slow response times and difficulties in getting refunds.
13. Hexomatic
Who is it for:
Anyone who doesn’t know about programming.
What is it:
Hexomatic is a versatile no-code web scraping and automation tool for users to collect data from websites without technical skills. It offers a wide range of features including scraping recipes, workflows, and automation.
Pros:
- Beneficial for those who are not technically inclined.
- Offers over 100 different automation tools, which can help streamline tasks like data extraction, sentiment analysis, and content generation.
Cons:
- Poor performance is reported when scraping protected sites.
- Customer support is unresponsive at times.
14. Easy Web Extract

Who is this for: Businesses with limited data needs, marketers, and researchers who lack programming skills.
Why you should use it: Easy Web Extract is a visual web scraping tool for business purposes. It can extract the content (text, URL, image, files) from web pages and transform results into multiple formats.
Pros:
- Easy to use for no-coders.
- One-time purchase fee of $59.99.
- A free trial and a free version are available.
- Effective in scraping content and images.
Cons:
- Initial setup can be challenging for users without a technical background.
- No integration options.
- Poor customer support.
15. Scrapy

Who is this for: Python developers with programming and scraping skills.
Why you should use it: As an open-source web crawling framework written in Python, Scrapy is widely used for various purposes, including data mining, information processing, and historical data analysis.
Pros:
- Highly flexible: allow users to customize the scraping process. It supports various middleware and pipeline components for processing scraped data.
- Asynchronous Networking: can handle multiple requests concurrently.
- Comprehensive documentation
- Strong community: new users can find solutions to their problems.
- Handle complex scraping tasks, including AJAX and JavaScript-heavy websites.
Cons:
- Difficult for people who don’t know Python.
- Extensive configuration and complexity setup for even a simple task. Other simpler tools might be more suitable.
- Requires significant computational power and memory for large-scale projects.
- Requires continuous maintenance.
16. Helium Scraper
Who is this for: Data analysts, marketers, and researchers who lack programming skills.
Why you should use it: Helium Scraper is a visual web data scraping tool that works pretty well, especially on small elements on the website. It has a user-friendly point-and-click interface which makes it easier to use.
Pros:
- offers a point-and-click interface。
- Supports exporting formats such as CSV, Excel, JSON, and SQLite.
- Users can automate data extraction tasks, set up crawlers, and schedule scraping activities.
- Regular expression support
Cons:
- Primarily designed for Windows.
- Might need extra technical expertise when using custom JavaScript for complex scenarios.
- Limited Customer Support.
- The upfront cost (one-time purchase) might be higher compared to subscription-based alternatives.
17. Grepsr
Who is it for: Businesses who don’t want to gather the data themselves
What is it: Grepsr offers end-to-end data solutions from initial consultation to data collection and maintenance.
Pros:
- Free from scraper setup, data extraction, and process maintenance.
- High data accuracy
- Scalable and tailored to various industries like e-commerce, real estate, and marketing.
- Prompt and personalized customer service
Cons:
- Premium service might be expensive for smaller businesses with prices starting from $350.
- High dependency on Grepsr might pose potential risks.
18. Pline.io
Who is it for: E-commerce companies who want to compare prices.
What is it: Pline.io is a web scraping tool that offers an easy and intuitive data extraction solution through a browser extension.
Pros:
- Easy setup and usage with no coding required.
- Supports both manual and automated data extraction.
- Offers unlimited data extraction for a limited time.
- Suitable for various use cases like dynamic price monitoring, market analysis, and sentiment analysis.
- Free plan available.
Cons:
- Supports only Chromium-based browsers.
- Limited data retention.
- No API access for the time being.
- No task scheduling and no cloud extraction.
- Face scalability problem for an extension.
19. Zyte
Who is this for: Developers who need tools and libraries for custom web scraping projects.
Why you should use it:
Zyte, previously known as Scrapinghub, is a web scraping and data extraction service that aims to assist businesses and individuals in gathering structured data from websites. It provides a variety of tools and services to simplify web scraping, such as a data extraction platform, automated data collection services, and open-source web scraping libraries.
Pros:
- Provides many tools and services, including Scrapy.
- Handle large-scale data extraction needs.
- Community support
- Can be integrated with various other tools and platforms.
Cons:
- Expensive, particularly for large-scale projects or enterprise-level usage.
- Steep learning curve for beginners.
20. Screen-Scraper

Who is this for: For businesses related to the auto, medical, financial, and e-commerce industries.
What is it:
Screen-scraper offers a web scraping service for businesses in many industries, such as medical, finance, auto, e-commerce, and real estate. Simulating how humans visit websites, Screen-scraper gets the information by automating actions like copying text, clicking links, entering data into forms, iterating through search results, and downloading various file types. It can also handle AJAX and integrate with a wide range of programming languages and operating systems.
Pros:
- Screen-scraper has been developed and refined over many years.
- It can run multiple operating systems including Windows, Linux, and macOS.
- Easily integrates with systems via APIs or direct database connections, supporting languages like .NET, Java, Ruby, and Python.
Cons:
- Price ambiguity
21. ScrapeHero
Who is this for: Investors, Hedge Funds, Market Analysts
Why you should use it: As a data company, ScrapeHero builds custom real-time APIs for websites that do not provide an API or have a rate-limited API. It also provides a web scraping service that delivers data at one stop as well as data analysis.
Pros:
- They utilize AI and ML for data quality checks.
- Support various data formats (JSON, CSV, XML, etc.) and can integrate with cloud storage solutions like AWS, Google Cloud, and Azure.
Cons:
- More expensive compared to simpler, do-it-yourself web scraping tools.
22. Web Content Extractor
Who is this for: Data analysts, marketers, and researchers who lack programming skills.
Why you should use it: Web Content Extractor is an easy-to-use web scraping tool for individuals and enterprises. It allows users to automate the process of data scraping, making it possible to collect data from various websites without manual intervention.
Pros:
- Requires no programming knowledge.
- Enable users to schedule scraping according to their needs.
- Offers multiple formats for exporting data, such as CSV, Excel, XML, and databases.
Cons:
- One-time payment. Might be expensive for small-task users.
- No API access
- Few anti-blocking techniques are available.
23. WebHarvy
Who is this for: Data analysts, Marketers, and researchers who lack programming skills.
Why you should use it: WebHarvy is a point-and-click web scraping tool. It’s designed for non-programmers. They provide helpful web scraping tutorials for beginners.
Pros:
- Easy to use point-and-click interface.
- Supports scraping of multiple types of data including text, images, and complex structured data.
- Users can automate tasks such as clicking links, selecting dropdown options, and inputting text.
- Includes JavaScript support, proxy server usage, and regular expressions for more customized scraping.
Cons:
- Slow performance in large data extractions.
- the extractor doesn’t allow you to schedule your scraping projects.
- Windows-Only
- No Built-in Captcha Solving or any anti-blocking techniques.
- It offers a lifetime license with no recurring monthly fees, which can be more economical in the long run.
24. Web Scraper.io – Chrome extension
Who is this for: Data analysts, Marketers, and researchers who lack programming skills.
Why you should use it: Web Scraper.io is a Chrome extension used to extract data from websites and store it in various formats such as CSV, JSON, and XLSX. For those who don’t know coding, it offers a user-friendly interface with a modular selector system for precise data extraction. It also provides integration options with platforms like Dropbox, Google Sheets, and Amazon S3 through its API and webhook access.
Pros:
- Point-and-click interface
- Data can be exported in multiple formats (CSV, JSON, XLSX), and integrations with popular platforms like Dropbox and Google Sheets are supported.
- Users can automate data extraction on an hourly, daily, or weekly basis.
- Free unlimited local use.
Cons:
- Poor performance: slow, prone to crashes, and struggles with large-scale data extraction tasks.
- The free version has significant limitations(scraping only a few pages).
- Little support: primarily relies on community support for troubleshooting.
25. Web Sundew
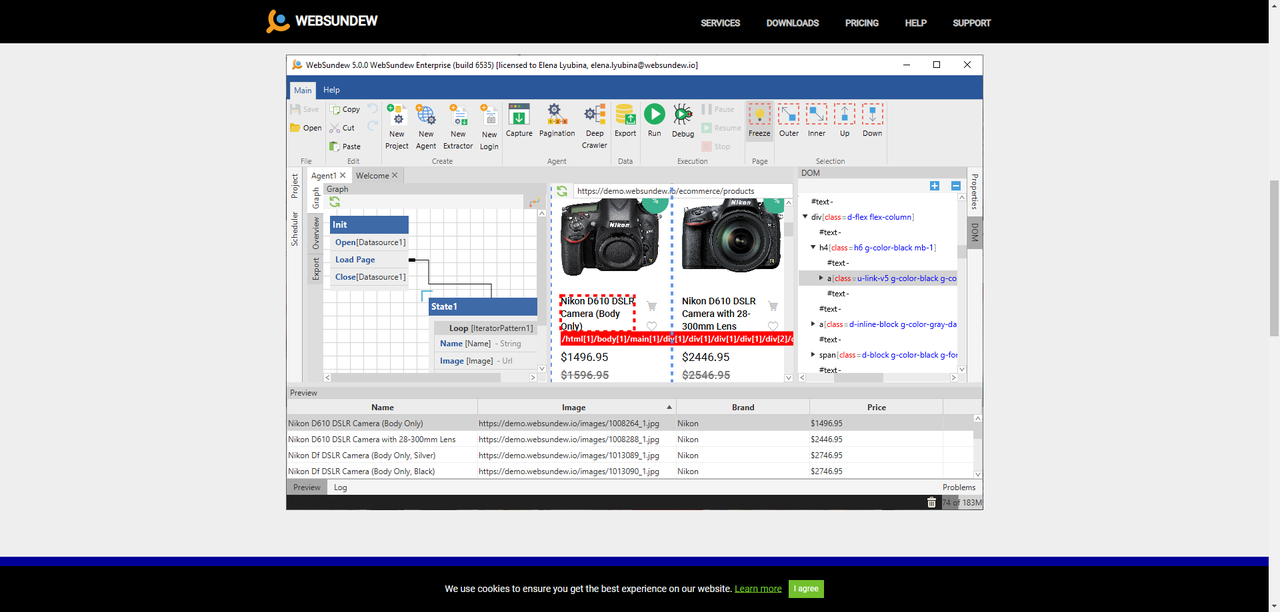
Who is this for: Enterprises, marketers, and researchers who know no code.
Why you should use it: WebSundew is a visual scraping tool that works for structured web data scraping. It supports data extraction from complex websites, including those with AJAX and JavaScript, and is capable of handling tasks like incremental extraction in the Enterprise version.
Pros:
- It has a user-friendly interface.
- Can scrape text, files, images, and PDFs.
- Includes capabilities like incremental extraction, API integration, and text recognition.
- Available for desktop and cloud versions, supporting Windows, Mac, and Linux.
Cons:
- Expensive with the basic plan charging at 99$ while offering little feature.
- Slow performance when dealing with extremely large datasets or very complex websites.
26. Web Robots

Who is this for: Data analysts, Marketers, and researchers who lack programming skills.
Why you should use it:
Web Robots is a comprehensive web scraping service that offers a variety of solutions for data extraction. Their services include a free extension tool, full data service, and SaaS which allows users to write their robots in JavaScript and jQuery.
Pros:
- offers both no-code and coding solutions.
- Extensive documentation and tutorials are available.
- Can scrape dynamic JavaScript-heavy websites and extract data from deep-web sources that require login and form filling.
Cons:
- More advanced features and custom robot writing might be challenging for beginners.
- Full service is quite expensive compared with a DIY solution.
- Some features rely heavily on Chrome, which may limit compatibility with other browsers or environments.
27. Selenium – Python library
Who is this for: python developers.
Why you should use it: As a powerful web scraping and test automation open-source framework, Selenium allows users to interact with web browsers, scrape dynamic content, automate repetitive tasks, test web applications, and gather data from websites. Except for flexibility, it also supports many programming languages and has a wide community.
Pros:
- Supports all major browsers (Chrome, Firefox, Safari, Internet Explorer, Edge) and can run on multiple platforms (Windows, Mac, Linux).
- supports several programming languages, including Java, C#, Python, Ruby, and JavaScript.
- Integrates well with other tools and frameworks, such as TestNG, JUnit, Maven, Jenkins, and Docker.
- Provides detailed control over web elements and user actions, making it suitable for complex test scenarios and sophisticated automation tasks.
Cons:
- Can be complex and challenging for beginners to learn and use.
- Need significant maintenance efforts in automated tasks to keep up with changes in the web application’s UI and functionality.
- Lack of built-in test reporting.
- Each browser requires a specific driver (e.g., ChromeDriver for Chrome), which adds an additional layer of complexity and potential compatibility issues.
28. Puppeteer – Node.js library
Who is this for: Web developers, automation enthusiasts, data analysts, and who are known about coding.
Why you should use it: Puppeteer is a Node.js library developed by Google. It offers a high-level API for controlling headless Chrome or Chromium browsers, which enables users to automate web interactions, scrape dynamic content, conduct browser testing, generate screenshots or PDFs, and more.
Read the article about thetop programming languagestoget more knowledge of coding.
Pros:
- Operates in a headless mode by default, making it faster and more efficient for automated tasks since it doesn’t need to render a graphical user interface.
- Excellent at handling JavaScript-heavy websites, single-page applications (SPAs), and dynamic content.
- Offers a simple and intuitive API.
- Can also run in a “headful” mode with a GUI, which is useful for debugging and development purposes.
Cons:
- Designed specifically for Node.js, which may not be suitable for developers using other programming languages.
- Running a full browser (even headlessly) can be more resource-intensive compared to other scraping tools that don’t render web pages.
- Primarily supports Chrome and Chromium.
- Can consume significant memory, especially when dealing with complex or large-scale scraping tasks.
29. Apify
Who is it for: People who know about programming and have a need for web scraping.
What is it:
Apify is a robust web scraping and automation platform that provides a comprehensive suite of tools for extracting and processing web data. Among all the features, they have an Actor store where developers can find hundreds of ready-made scrapers with clear and detailed instructions on how to set them up.
Pros:
- Handles complex websites with AJAX and JavaScript.
- Integration supported
- Strong user community and extensive documentation
Cons:
- Difficult for users without a technical background.
- Price ambiguity
30. Oxylabs.io
Who is it for: Anyone who needs proxy service for their web scraping projects.
What is it:
Oxylabs is a leading company that provides residential and data center proxies. For people who don’t want to do script writing, they also offer scraper APIs and data-gathering services.
Pros:
- High success rates proxies.
- Easy to scale your scraping projects. Suitable for businesses that require a large amount of data.
- JavaScript rendering and IP rotation supported
Cons:
- It can be expensive for small businesses and individuals.
- Complex to use for people without a technical background.
How does web scraping software work?
Most web scraping software automates the process of collecting data from web pages by accessing web content, extracting specific data points, and saving this information in a structured format, such as CSV, Excel, or a database.
There are four types of web scraping software: browser extension, desktop application, cloud-based software, API, and libraries. Though some tools/platforms might cross several types and provide a more comprehensive solution, most of them are dedicated to just one field. Below, I have listed the top 30 scraping software/platforms that are free or provide a free trial. And I have recorded my experience for your reference with pros and cons.
FAQs about Web Scraping Tools
- Which is the best data scraper tool?
The “best” tool depends on your needs. If you want an easy, no-code solution, Octoparse is one of the most popular options because it offers pre-built templates, cloud scraping, and point-and-click extraction. For developers who prefer customization, open-source libraries like BeautifulSoup or Scrapy are powerful alternatives.
- Are data scrapers illegal?
Data scraping itself is not illegal — it depends on how and where you use it. Extracting publicly available information is usually fine, but scraping private data, copyrighted content, or ignoring a website’s Terms of Service can cause legal issues. Always check local laws and site policies before scraping.
- What is a data scraping tool?
A data scraping tool is software that automatically extracts information from websites. Instead of copying and pasting data manually, these tools collect text, images, links, or structured data and export it into spreadsheets, databases, or APIs for further use.
- Can ChatGPT scrape data from a website?
No, ChatGPT cannot directly scrape websites. It can help you write or debug code for scraping, or suggest the right tools and methods, but the actual data extraction must be done with a scraper like Octoparse, Scrapy, or BeautifulSoup.
- What is the difference between data scraping software and web scraping software?
Data scraping software can extract information from many sources. Web scraping software is a type of data scraper focused only on websites. The terms are often used interchangeably, but web scraping is more specific to online data.
Closing Thoughts
Getting the data from target websites involves more effort. While there are numerous tools and services out there to choose from, it is better to figure out your scraping requirements and budget first.
Things like data volume, targeted site structures, scraping intervals, developer resources, etc need to be taken into consideration. If you are not sure, you can check out Octoparse, which provides the simplest yet powerful solution that is worth your budget.




