For many people, python might be the first word that comes to their minds when talking about data crawling. It makes sense since all the crawling software and APIs did not appear until 2-3 years ago. If you prefer to scrap data the traditional and yet the most flexible way, then this article can provide the most comprehensive assistance.
What is a Web Crawler?
Think of the internet as an enormous library. A librarian uses a system to find books. Likewise, a web crawler (or spider) navigates the internet to gather information from websites. Why does this matter? Because in our data-driven world, the ability to extract and analyze information can lead to better decisions in business, research, and technology, and thus get an edge or occupy the market ahead of time.
There are two primary ways to crawl websites: coding and no-coding methods. So developer or not developer, you will grab something home from this article.
What is Python?
Python is one of the programming languages—simple yet powerful, beginner-friendly yet robust enough for the pros. Though it is easy to read and understand, it manages many complicated aspects of programming automatically. That’s why many people choose Python to start their coding journey, especially when it involves crawling websites.
Why Use Python for Web Crawling?
Python has several libraries designed to simplify tasks like web crawling. Libraries are collections of pre-written code that we can utilize to perform specific operations. For web crawling, libraries like BeautifulSoup and Scrapy can save us from building a web scraper from scratch.
Steps on Building a Crawler with Python (example included)
For no coding solution, scroll straight to: No Coding Alternative: Octoparse’s Scraping Templates
Here comes the Braver’s Journey:
- Set Up Your Python Environment
Before you begin coding, make sure Python and pip (Python’s package installer) are installed on your machine.
Here’s how you can prepare your environment:
- Install Python: Download and install Python from python.org.
- Install Necessary Libraries: Open your terminal or command prompt and install the BeautifulSoup and requests libraries using pip. These libraries will help in making HTTP requests and parsing HTML documents.
- Identify the Data You Need
Determine what specific data you want to extract. For example, from Yellow Pages, you might want to scrape information like business names, addresses, phone numbers, or website URLs. Understanding what you need will help you focus on the elements from the extracted HTML.
- Write Your Web Scraping Script
Once your environment is set up, you can start coding your scraper. Here’s a step-by-step process:
- Import Libraries: First, import the necessary libraries in your Python script.
- Make HTTP Requests: Use the
requestslibrary to send a GET request to the website you want to scrape. Replace'https://example.com'with the URL of the website you have permission to scrape.
In the Yellow Page example, we can replace the default URL 'https://example.com'to ‘https://www.yellowpages.com/search?search_terms=restaurant&geo_location_terms=New+York%2C+NY’
- Parse the HTML Content: Use
BeautifulSoupto parse the fetched HTML content. Then you can navigate and search through the HTML for the data you want.
- Extract Specific Data:
In Yellow Page example, if you are looking for business names and contact information, you might look for specific class attributes that enclose this data.
- Store the Extracted Data
You might want to save the data for further analysis or processing. In this case, you can use pandas to easily store the extracted data in a structured format like a CSV file.
- Handle Possible Errors
While there will be potential errors in your code, such as network problems or parsing errors, you can use try-except blocks to catch and respond to exceptions gracefully. Check the following:
Common Problems and Solutions
Crawling with python is not that easy, you might hit some roadblocks:
- IP Blocks and CAPTCHAs
Websites may block your IP address if they detect unusual or excessive traffic coming from a single source, which they often interpret as potential abusive behavior. Sometimes, CAPTCHAs may also be employed to verify if you are a human or a bot.
Solutions:
- Proxies: Proxies can be used to route your requests through different IP addresses. With the load distributed, your requests will appear more natural. There are many platforms that offer proxies at a price. And you can also turn to python’s
requestslibrary for a list of proxies and rotate them for each request.
- Rotating User-Agents: Varying the user-agent can also help disguise your scraping bot as a regular browser. Libraries like
fake_useragentcan generate random, realistic user-agent strings and lower your chance of being blocked.
- Speed and Efficiency
If you make too many requests in a short period, the website can be overloaded and you will get a slower response times both for your scraper and the website itself. This can also increase the chances of getting your IP banned.
Solutions:
- Rate Limiting: Try to implement delays between requests to reduce the load on the website’s server. For example, python’s
time.sleep()function can be used to add pauses.
- Asynchronous Requests: It can handle multiple requests more efficiently without blocking the execution of your program. Check libraries
aiohttpin this regard.
- Respecting
robots.txt
The robots.txt file on a website specifies which parts of the site can be accessed by bots. If you ignore these rules, you might get yourself legal issues and banning.
Solutions:
- Check
robots.txtManually: Before you begin scraping, manually check therobots.txtfile of the website (e.g.,https://www.yellowpages.com/robots.txt) to see if scraping is allowed for the parts of the site you are interested in. - Automate Compliance: You can use libraries like
robotparserin Python to read and understand therobots.txtautomatically, making sure your scraper respects the specified rules.
No Coding Alternative: Octoparse’s Scraping Templates
If the above programming language puzzles you and even brings you headache, then the coding method might not be your thing. Just like there is more than one road leading to Rome, there is more than one method to get your information ready. There are preset templates that can suit your needs with just a few clicks and parameters. For example, Octoparse’s Yellow Pages Scraper.
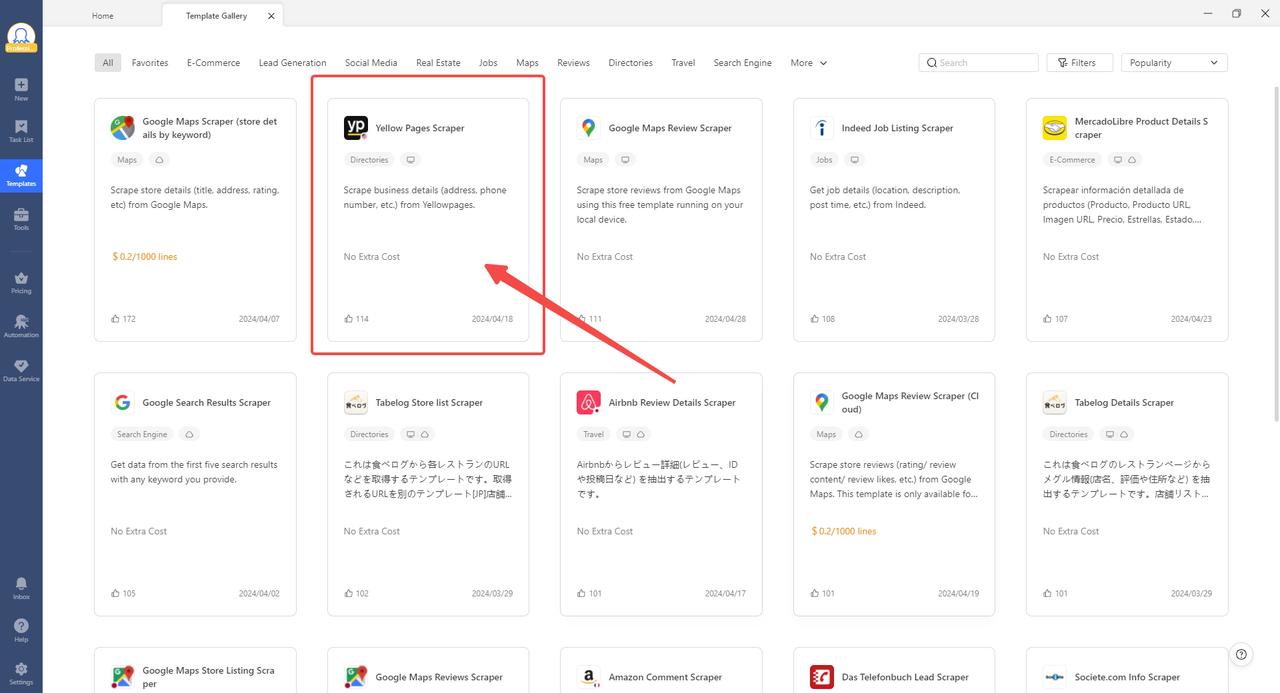
Now you can see this one-tool-fix-it-all. Choose the template that can solve your problems by navigating through the templates market.
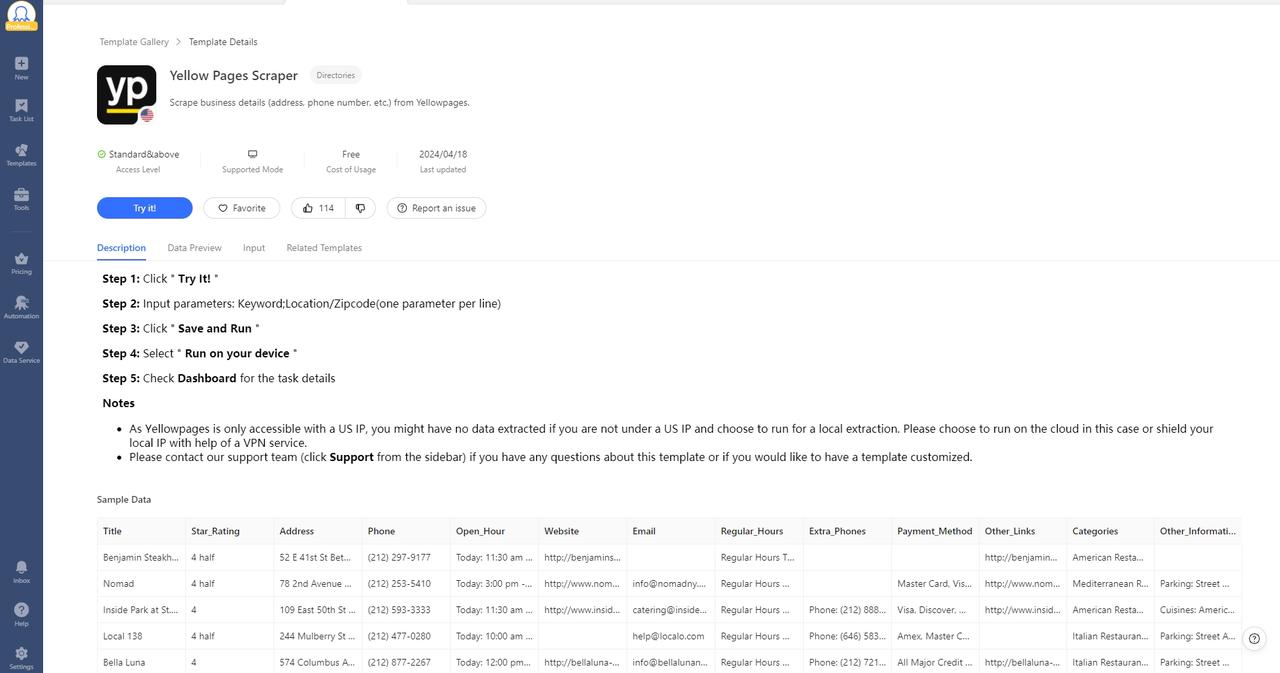
For example, we still choose this Yellow Page Scrapers to help us do the job. Follow the steps in the interface and enter your parameters, such as keyword, location/zipcode. Next click “Save and Run”. Then the tool can extract the data for you within minutes.
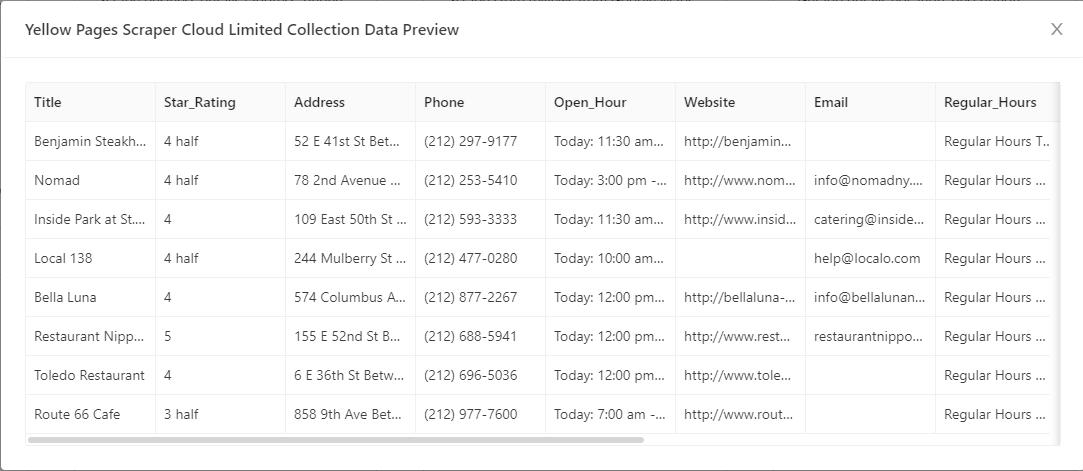
Once the scraping is complete, export the data into any format you want such as Excel, CSV, HTML, JSON, XML, or export into database such as Google Sheet, MySql, SqlServer.
Conclusion
Hopefully, this article can help you in scraping the data you need. Though there is more than one way to get your desired data, be it coding, API, or software extraction, make sure that the data is collected and used responsibly by respecting privacy, legality, and the rights of the data owners. If you’re not sure whether your move is responsible, it’s always safer to use a tool like Octoparse, which is GDPR compliant. For pages or information that are protected, you will not get access to them via Octoparse. This will save you potential legal issues. Having a tool deals with all the legality checking and blocking issues for you, you will be left to focus on what really matters.




