In this article, I want to share with you how to crawl Twitter through API or with a web crawler and deal with the data for sentiment analysis.
#Step1: How to Gather Twitter Data
When we think of sentiment analysis, what comes first to our mind is where and how we can crawl oceans of data.
Take one of the most popular social media websites Twitter as an example. There are several methods that we can crawl data from Twitter – Build a web crawler on our own by programming, or choosing an automated web crawler, like Octoparse, Import.io, etc. We can also use the public APIs provided by certain websites to get access to their dataset.
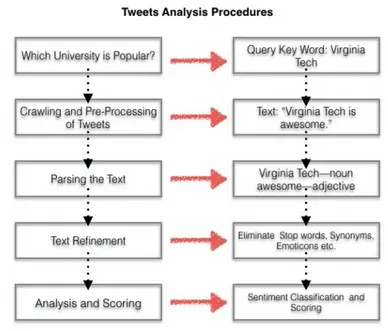
Get it with API
First, it is well known that Twitter provides public APIs for developers to read and write tweets conveniently. The REST API identifies Twitter applications and users using OAuth. Thus, we can utilize twitter REST APIs to get the most recent and popular tweets.
Twitter4j is imported to crawl twitter data through twitter REST API. Twitter data can be crawled according to a specific time range, location, or other data fields. The data crawled will be returned as JSON format. Note that APP developers need to generate twitter application accounts, so as to get the authorized access to twitter API.
By using a specific Access Token, the application made a request to the POST OAuth2 to exchange credentials so that users can get authenticated access to the REST API. This mechanism allows us to pull users’ information from the data resource. Then we can use the search function to crawl these structured tweets related to university topics.
Then, I generated a query set to crawl tweets, displayed as the figure below. I collected University Ranking data of USNews 2016, which includes 244 universities and their rankings. Then, I customized the data fields I need to use for crawling tweets into JSON format.

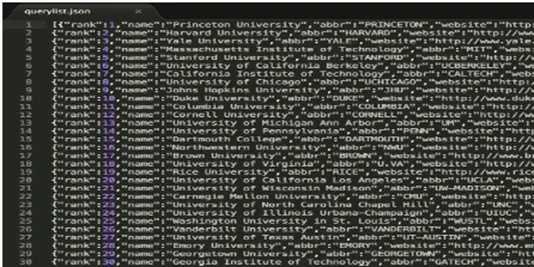
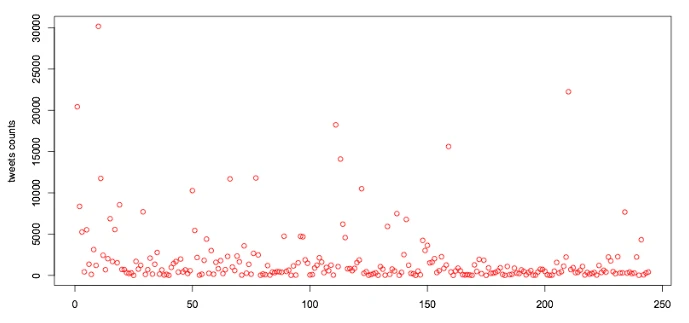
In this case, I extracted 462,413 tweets results totally. The number of most universities’ tweets crawled is less than 2000.
Get it With a Web Scraping Tool
API may not be familiar to everyone and could be tricky for someone without any coding skills. For your reference, I’d like to propose an automated web crawler tools that can help you crawl websites without any coding skills, like Octoparse.
If you need help to gather Twitter data with Octoparse:
> Scraping Experience Shared by our users
#Step2: Twitter Sentiment Analysis
Let’s go back to the University Ranking of my designed application. Ranking technology in my application is to parse tweets crawled from Twitter and then rank related tweets according to their relevance to a specific university. I want to filter high-related tweets (topK) to do the Sentiment Analysis, which will avoid trivial tweets that make our results inaccurate.
You can rank them based on TF-IDF similarity, text summarization, spatial and temporal factors, or you can choose the machine learning ranking method. Even Twitter itself provides a method based on time or popularity. However, we need a more advanced method that can filter out the most spam and trivial tweets.
In order to measure the trust and popularity of a tweet, I use the following features from tweets: retweet counts, follower counts, and friend counts. Assuming that a trust tweet should be posted by a trust user. And a trust user should have enough friends and followers, then a popular tweet should have high retweet-count.
I build a model combining trust and popularity (TP Score) for a tweet. Then I rank those tweets based on TP score. Note that report news usually has a high retweet count, and this type of score will be useless for our Sentiment Analysis. Thus, I assigned a relatively lower weight on this portion when computing the TP score. The formula designed is shown below. The tweets we crawled are filtered by query words and posting time. All we need is to consider the retweet counts, follower counts, friend counts.
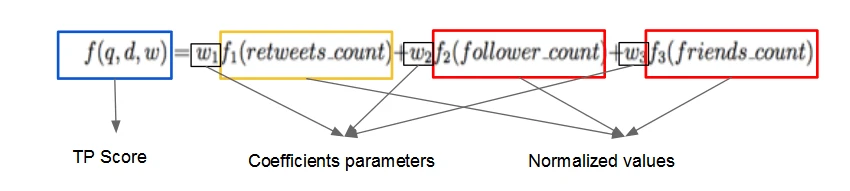
I make my own university ranking according to public reputation which is represented by sentiment score. However, public reputation is only one of the factors that should be considered when evaluating a university. Thus, I want to present an overall ranking that combines both commercial ranking and our ranking.
There are three main types of tweets texts:

Sentiment Score: The Sentiment Score is calculated for public reputation. The positive rate of each university was used as the sentiment score for the public reputation ranking. The formula below defines the positive rate. Note that the negative polarity is not considered since it is equal to zero.
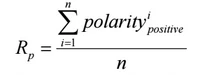
Where n is the total number of tweets for each university; And represents the positive polarity for a tweet, 4.
After I complete Sentiment Analysis, I would proceed to build a classifier for Sentiment Analysis using a machine learning algorithm. I will discuss it in the next article regarding the Maximum Entropy classifier.




