XPath is a major element in the XSLT standard, and it can be used to navigate through elements and attributes in an XML document. XPath plays an important role in web scraping to get more accurate data. Rewriting XPath can help you deal with missing pages, missing data, duplicates, etc. While XPath may look intimidating at first, it need not be. In this article, I will briefly introduce what is XPath and how it can be used to fetch the data you need by building tasks that are accurate and precise.
What Is XPath
XPath (XML Path Language) is a query language for selecting elements from an XML/HTML document. It can help you find an element from the whole document precisely and quickly.
Web pages are generally written in a language called HTML. If you load a web page on a browser (Chrome, Firefox, etc), you can easily access the corresponding HTML doc by hitting the F12 key. Everything you see on the webpage can be found within the HTML, such as an image, blocks of text, links, menus and etc.
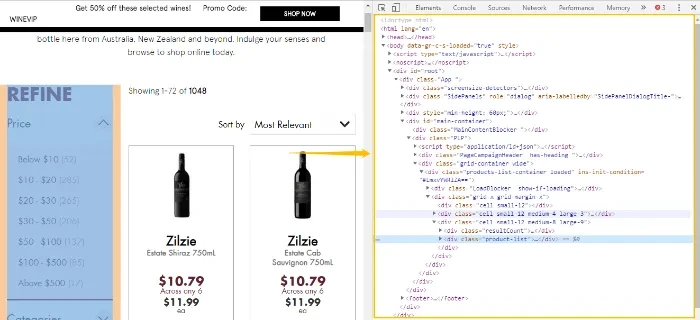
XPath is the most commonly used language when people need to locate an element in an HTML doc. It can be easily understood as the “path” to find the target element within the HTML doc. To further explain how XPath works. Let’s look at an example.

The image shows part of an HTML doc.
HTML has different levels of elements, just like a tree structure. In this example, Level 1 is bookstore and level 2 is book. Title, author, year, price are all level 3.
Text with angle brackets(<bookstore>) is called a tag. An HTML element usually consists of a start tag and an end tag, with the content inserted in between.
<tagname>Content goes here…</tagname>
XPath uses “/” to connect tags of different levels from the top to the bottom in order to specify the location of an element. For our example, if we want to locate the element “author”, the XPath would be like:
/bookstore/book/author
If you are having trouble understanding how it works, think about how we go about finding a particular file on our computer.
To find the file named “author”, the exact file path is \bookstore\book\author. Look familiar?
Every file on the computer has its own path, so are the elements on a web page. With XPath, you can find the page elements quickly and easily just like finding a file on your computer.
The XPath that starts from the root element (the top element in the doc) and goes through all the elements in between to the target element is called an Absolute XPath.
Example: “/html/body/div/div/div/div/div/div/div/div/div/span/span/span…”
Absolute path can be long and confusing, so to simplify Absolute XPath, we can use “//” to reference the element we want to start the XPath with (also known as a short XPath). For example, the short XPath for /bookstore/book/author can be written as //book/author. This short XPath would look for the element book regardless of its absolute location in the HTML, then go one level down to find the target element author.
How Does XPath Use in Octoparse
Octoparse is a no-coding web scraping tool to help you extract data from any website easily and quickly. It has both easy mode and advanced mode, which means that you can choose the non-coding data scraping templates or customize the web crawler by yourself.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
When you need to scrape webpage data using Octoparse, there are usually 3 steps:
Step 1: Download and register the no-coding web scraper Octoparse for free.
Step 2: Open the webpage you need to scrape and copy the URL. Paste the URL to Octoparse and start auto-scraping. Customize the data field from the preview mode or workflow on the right side.
Step 3: Start scraping by clicking on the Run button. The scraped data can be downloaded as excel to your local device.
Scraping web pages with Octoparse is actually to scrape elements from HTML docs. XPath is used to locate target elements from the doc. Let’s take the pagination action as an example.
After we select the next button to build the pagination action, Octoparse would generate an XPath to locate the next button, so that it knows which button to click.
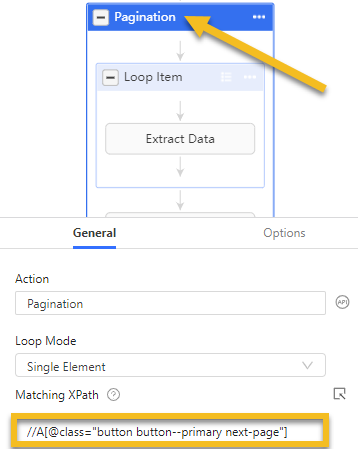
XPath helps the crawler to click the right button or to scrape the target data. Any action you want Octoparse to do is based on the underlying XPath. Octoparse can generate XPaths automatically but the auto-generated ones do not always work well. That’s why we need to learn to rewrite XPath.
When dealing with issues like missing data, endless loop, incorrect data, duplicative data, next button not getting clicked, etc, there’s a good chance you’d fix these issues easily by re-writing the XPath.
How to Write an XPath (Cheat Sheet Included)
Before we start writing an XPath, let’s first cover some key terms. Here’s a sample HTML we’ll use to demonstrate.

Attribute/value
An attribute provides additional information about an element and is always specified in the start tag of the element. An attribute usually come in name/value pairs like: name=”value”. Some of the most common attributes are href, title, style, src, id, class, and many more. You can find the complete HTML attribute reference.
In our example, id=”book” is the attribute of the <div> element and class=”book_name” is the attribute of the <span> element.

Parent/child/sibling
When one or more HTML elements are contained within an element, the element that contains the other elements is called the parent, and the contained element is a child of the parent. Each element has only one parent but it may have zero, one or more children. Children are found between the start tag and the end tag of the parent.
In our example, the <body> element is the parent of the <h1> and <div> elements. The <h1> and <div> elements are children of the <body> element.

The <div> element is the parent of the two <span> elements. The <span> elements are the children of the <div> element.

Elements that have the same parent are called siblings. The <h1> and <div> elements are siblings as they have the same parent <body>.

The two <span> elements, both indented under the <div> element are also siblings.

Let’s look at some common use cases!
Write an XPath to locate the Next Page button
So first we’ll have to inspect the Next Page button in the HTML closely. In the sample HTML below, there are two things that stand out. First, there is a title attribute with the value “Next” and second, the content “Next”.
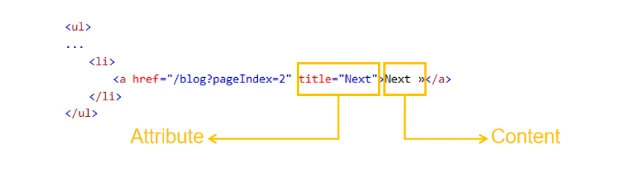
In this case, we can use either the title attribute or the content text to target the Next Page button in the HTML.
The XPath that locates the <a> element that has a title attribute with the value “Next” would look like this: //a[@title=”Next”]
This XPath basically says, go to the <a> element(s) whose title attribute is “Next”. The @ symbol is used in the XPath to target an attribute.
Alternatively, the XPath that locates the <a> element that has “Next” included in the content looks like this: //a[contains(text(), “Next”)]
This XPath says, go to the <a> element(s) whose content contains the text “Next”.
You can also use both the title attribute and the context text to write the XPath.
//a[@title=”Next” and contains(text(), “Next”)]
This XPath says, go to the <a> element(s) that has a title attribute with value “Next” and whose content includes the text “Next”.
Write an XPath to locate loop item
To target a list of items on a web page, it is important to look for the pattern among the list items. Items of the same list generally share the same or similar attributes. In the sample HTML below, we see that all <li> elements have similar class attributes.

Based on the observation, we can use contains(@attribute) to target all items of the list.
//li[contains(@class,”product_item”)]
This XPath says,go to the <li> element(s) whose class attribute contain “product_item”.
Write an XPath to locate data fields
Locating a particular data field is very similar to locating the Next Page button using text() or attribute.

Say if we want to write an XPath that locates the address in the sample HTML above. We can use the itemprop attribute that has the value “address” to target the particular element.
//div[@itemprop=”address”]
This XPath says, go to the <div> element that has itemprop attribute with the value “address”.
There’s another way to approach this. Notice how the <div> element containing the actual address is always found under its sibling <div> element, one that has the content “Location:”. So we can first locate the “Location” text and then select the first sibling that follows.
//div[contains(text(),”Location”)]/following-sibling::div[1]
This XPath says, go to the <div> element that has “Location” included in the content, then go to its first sibling <div> element.
Now, you may have already noticed there is actually more than one way to target an element in the HTML. This is true just like there is always more than one path to any destination. The key is to use the tag, attributes, content text, siblings, parent, or whatever helps you locate the target element in the HTML.
To make things easier for you, here is a cheat sheet of helpful XPath expressions to help you quickly target any elements in the HTML.
|
Expression |
Example |
Meaning |
|
* Matches any elements |
//div/* |
Selects all the child element of the <div> element |
|
@ Selects attributes |
//div[@id=”book”] |
Selects all the <div> elements that have an “id” attribute with a value of “book” |
|
text() Finds elements with exact text |
//span[text()=”Harry Potter”] |
Selects all the <span> elements whose content is exactly “Harry Potter” |
|
contains() Selects elements that contain a certain string |
//span[contains(@class, “price”)] |
Selects all the <span> elements whose class attribute value contains “price” |
|
//span[text(),”Learning”] |
Selects all the <span> elements whose content contains “Learning” | |
|
position() Selects elements in a certain position |
//div/span[position()=2] //div/span[2] |
Selects the second <span> element that is the child of the <div> element |
|
//div/span[position()<3] |
Selects the first 2 <span> elements that are the child of <div> element | |
|
last() Selects the last element |
//div/span[last()] |
Select the last <span> element that is the child of <div> element |
|
//div/span[last()-1] |
Selects the last but one <span> element that is the child of <div> element | |
|
//div/span[position()>last()-3] |
Selects the last 3 <span> elements that are the child of <div> element | |
|
not Selects elements that are opposite to the conditions specified |
//span[not(contains(@class,”price”))] |
Selects all the <span> elements whose class attribute value does not contain price |
|
//span[not(contains(text(),”Learning”))] |
Selects all the <span> elements whose text does not contain “Learning”. | |
|
and Selects elements that match several conditions |
//span[@class=”book_name” and text()=”Harry Potter”] |
Selects all the <span> elements whose class attribute value is “book_name” and the text is “Harry Potter” |
|
or Selects elements that match one of the conditions |
//span[@class=”book_name” or text()=”Harry Potter”] |
Selects all the <span> elements whose class attribute value is “book_name” or the text is “Harry Potter” |
|
following-sibling Selects all siblings after the current element |
//span[text()=”Harry Potter”]/following-sibling::span[1] |
Selects the first <span> element after the <span> element whose text is “Harry Potter” |
|
preceding-sibling Selects all siblings before the current element |
//span[@class=”regular_price”]/preceding-sibling::span[1] |
Selects the first <span> element before the <span> element whose class attribute value is “regular_price” |
|
.. Selects the parent of the current element |
//div[@id=”bookstore”]/.. |
Select the parent of the <div> element whose id attribute value is “bookstore” |
|
| Selects several paths |
//div[@id=”bookstore”] | //span[@class=”regular_price”] |
Selects all the <div> elements whose id attribute value is “bookstore” and all the <span> elements whose class attribute value is “regular_price”. |
*Note that the attribute and text value are all case-sensitive.
*For a more exhaustive list of XPath expressions, check this out.
Matching XPath and Relative XPath (for Loop)
So far we’ve covered how to write an XPath when you need to extract an element from a webpage directly. There are times, however, you may need to first build a list of target items then extract the data from each item. For example, when you need to extract data from results pages like this (https://www.bestbuy.com/site/promo/tv-deals).
In this case, you are not only required to know the Matching XPath (which you’d use for capturing element directly), but also the Relative XPath, one that specifies the location of the specific list item relative to the list.
In Octoparse, when you modify the XPath of a data field, you will see there are two XPath boxes.
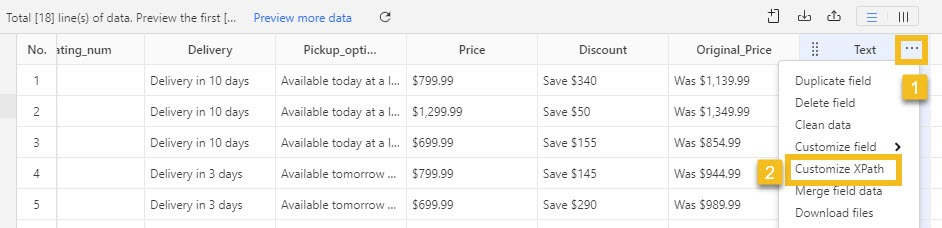
Matching XPath is used when we extract data from the web page directly.
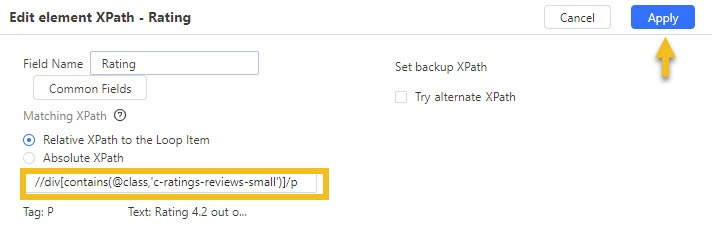
Relative XPath is used when we extract data from a loop item. The Relative XPath in Octoparse is an additional part of the Matching XPath relative to Loop Item XPath.

For example, if we want to create a loop list of <li> elements and scrape an element contained within the individual <li> elements in the list, we can use the XPath //ul[@class=”results”]/li to locate the list.
Suppose, the Matching XPath of an element on the list is //ul[@class=”results”]/li/div/a[@class=”link”].
So in this case, the Relative XPath should be /div/a[@class=”link”]. Or we can simplify this Relative XPath using “//” to //a[@class=”link”]. It is always recommended to use “//” when writing Relative XPath as it would make the expression more concise.
Now you may have already noticed that when the XPath for the loop list and the relative XPath are combined into one XPath, there you have precisely the Matching XPath for the loop item.
4 Simple Steps to Fix Your XPath
Step 1: Open the webpage using a browser with an XPath tool (one that allows you to view the HTML and lookup an XPath query). XPath helper(a Chrome extension) is always recommended if you use Chrome.
Step 2: Onece you have the web page loaded, inspect the target element in the HTML.
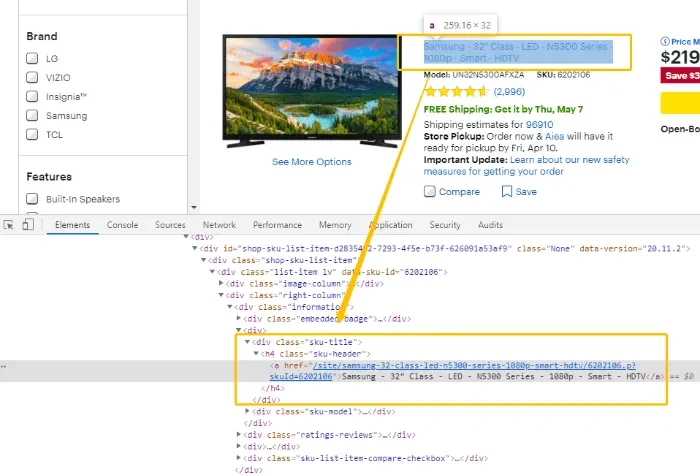
Step 3: Inspect the HTML element closely, as well as the elements nearby. Do you see anything that stands out and may help you identify and locate the target element? Perhaps a class attribute like class=”sku-title” or class=”sku-header”?

Use the cheat sheet above to write an XPath that selects the element exclusively and precisely. Your XPath should only match the target element(s) and nothing else on the entire HTML doc. Using XPath helper, you can always test to see if the re-written XPath is working right.
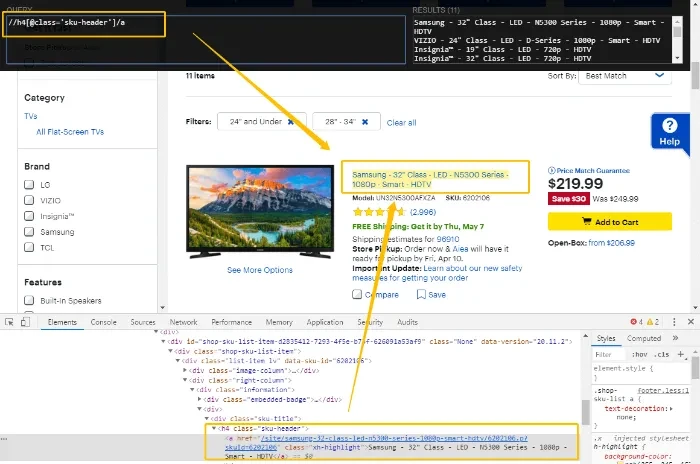
Step 4: Replace the auto-generated XPath in Octoparse.
XPath Troubleshooting Tutorials
In most cases, you don’t need to write the XPath on your own. But there are some situations where you might need to do some modification to scrape more accurately.
Loop issues
1) Missing items in the loop: Infinitive Scroll has setup but no new elements added to the list?
Data fields issues
1) Scrape to a wrong field: Data fetched to the incorrect data fields?
Other XPath Tools
It is not easy to check the HTML code directly in Octoparse, so we need to use some other tools to help us generate an XPath.
Chrome/any browser
You can get an XPath for an element easily with any browser. Let’s take Chrome as an example.
- Open the web page in Chrome
- Right-click on the item you want to find the XPath of
- Choose “inspect” and you will see Chrome DevTools
- Right-click on the highlighted area on the console.
- Go to Copy -> Copy XPath
But the XPath copied sometimes is an Absolute XPath when there is no attribute or the attribute value is too long. You may still need to write the correct XPath.
XPath Helper
XPath Helper is a superb chrome extension that allows you to look up XPath by simply hovering over the element from the browser. You can also edit the XPath query directly in the console. You’ll get the result(s) immediately so you know if your XPath is working correctly or not.
For more tutorials about XPath:




