Web scraping is an invaluable technique for businesses and researchers looking to extract large amounts of data from websites. Amazon, being one of the largest e-commerce platforms globally, is a prime target for web scrapers seeking product information, pricing trends, reviews, and market insights.
However, scraping Amazon data can be challenging due to the implementation of CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart), which is designed to block automated bots.
In this article, you can learn how to bypass Amazon CAPTCHA easily and continue scraping without disruption. Also, you can try the most efficient way to scrape data from Amazon.
What is Amazon CAPTCHA and Why Does Amazon Use It
Amazon CAPTCHA is a security feature used to differentiate between human users and automated bots. It is triggered when Amazon detects suspicious activity, such as rapid, repetitive requests from a single IP address. CAPTCHA challenges require users to prove they are human by completing tests like identifying objects in images or typing distorted characters.
Why does Amazon use CAPTCHA
- Preventing Bots: CAPTCHA is primarily used to prevent automated bots from scraping Amazon’s data or performing harmful activities, such as data harvesting, content scraping, or conducting malicious attacks.
- Ensuring Website Security: By blocking bots, Amazon ensures that only legitimate users can access their platform, thereby preventing DDoS attacks (Distributed Denial of Service) and ensuring that servers are not overloaded.
- Protecting User Experience: CAPTCHA helps ensure that human users can enjoy a seamless experience on the site without interference from bots, which could degrade site performance.
Common Challenges with Scraping Amazon Due to CAPTCHA
When scraping Amazon, the most common obstacles users face due to CAPTCHA include:
- CAPTCHA Prompts: As soon as a bot is detected, Amazon will present a CAPTCHA challenge, which requires human intervention to solve. This interrupts the scraping process and significantly delays data collection.
- IP Blocking: If the scraping tool or bot sends too many requests in a short period from the same IP address, Amazon will temporarily block the IP, making it impossible to continue scraping.
- Rate Limiting: Amazon can throttle the request rate, limiting the number of requests that can be sent in a specific time frame. This results in slower scraping speeds and reduced efficiency.
- Complexity of CAPTCHA: Some CAPTCHAs are designed to be difficult for machines to solve. This can create delays and necessitate the use of manual intervention or external services to bypass them.
These challenges can make it difficult for scrapers to gather data efficiently, especially when trying to extract large volumes of information from Amazon.
Learning about the legacy problems of scraping Amazon before your data extraction.
How to Bypass Amazon CAPTCHA Without Coding
One of the most effective ways to bypass Amazon CAPTCHA is by using a dedicated web scraping tool such as Octoparse. Octoparse is an easy-to-use, powerful web scraping tool that helps you automate the scraping process, bypass CAPTCHA challenges, and gather data effortlessly. It also provides preset data scraping templates, which can help you finish the data extraction with only a few parameters.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
Tips to solve Amazon CAPTCHA during Octoparse scraping
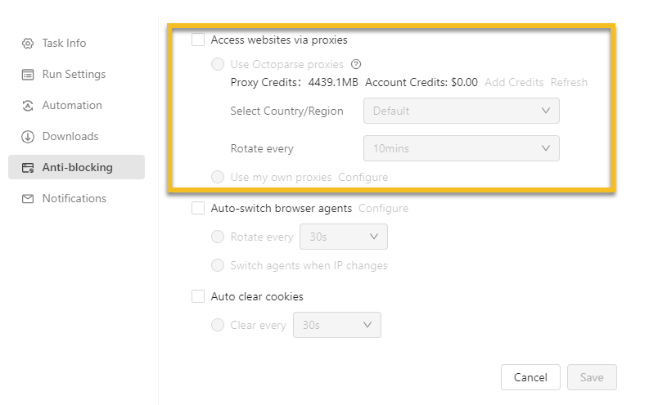
Proxy Rotation
Octoparse supports proxy management, enabling you to rotate IP addresses during scraping. By using different IPs for each request, you can avoid being flagged as a bot and prevent Amazon from blocking your scraping efforts.
Read about how to set IP proxies.
Cloud-based Scraping
With Octoparse’s cloud scraping feature, you can run your scraping tasks on the cloud, ensuring that you’re not restricted by local IP limitations or network bandwidth issues. This also reduces the risk of IP blocking by Amazon.
How to use Octoparse cloud extraction function?
Here are more tips can avoid being blocked while web scraping, read about the article: How to Scrape Data Never Getting Blocked.
Online templates for Amazon data scraping
If you are looking for an easier way to scrape Amazon data, Octoparse data scraping templates can save you time and energy. You can use those templates without downloading anything, but just enter the target URLs and keywords you need to scrape and Octoparse templates can finish the whole process. No matter the product details, listings, prices, stocks, or reviews data can be collected without blocking. Try the Amazon scraping templates below.
https://www.octoparse.com/template/amazon-product-scraper-by-keywords
https://www.octoparse.com/template/amazon-reviews-scraper
Final Thoughts
Bypassing Amazon’s CAPTCHA for web scraping doesn’t have to be a complicated task. Using tools like Octoparse, which handles CAPTCHA challenges automatically, makes it easier to collect valuable data from Amazon efficiently. The features of Octoparse, such as proxy rotation and cloud-based scraping, further ensure uninterrupted data extraction, even at scale.
If you are looking for a reliable and efficient solution to bypass Amazon CAPTCHA and scrape data smoothly, Octoparse is the ideal tool. Start using it today to streamline your web scraping tasks and collect the insights you need without interruptions.