As a well-known online publishing platform, Medium covers a wide range of topics including technology, entrepreneurship, politics and creative writing. Co-founder of Twitter Evan Williams started Medium in 2012 as a way for authors, both professional and amateur, to share their stories and ideas with a worldwide audience. Its simple and intuitive user interface has attracted millions of users from all over the world.
Web scraping Medium is frequently used to collect a large amount of information, including articles, author profiles, and more for content analysis and other research uses. It offers insightful information on writers’ involvement, topic popularity, and content trends, all of which are useful for academic study, market research, journalism, and AI training. Let’s now take a look at the main reasons why users would wish to scrape Medium.
Top Reasons for Scraping Medium
Content Analysis: Medium is a great resource for content analysis because it provides a wide range of articles on a variety of subjects. Researchers, marketers, and content strategists can gain insights, determine prevailing patterns, and determine the level of popularity of particular themes by methodically analyzing and interpreting Medium content. This data-driven method can be used to uncover popular topics or issues for focused marketing efforts, provide guidance for content development tactics, and even help shape plans or suggestions for policies in particular fields.
Market Research: As one of the best places to find unique ideas, opinions, and experiences is Medium’s ecosystem, which is home to a large number of thought leaders, innovators, and influencers in the industry. Businesses can obtain intimate insights on audience preferences, market dynamics, new industry trends, and creative ideas by scraping Medium’s content. The collection of rich content is a goldmine of information that can boost a company’s ability to compete in its market by assisting with decision-making.
Competitive Analysis: It’s critical to stay current on industry trends and strategies in the fast-paced world of business. Medium is a platform worth investigating for competitive analysis because companies and thought leaders often publish content related to their areas of expertise. Businesses can monitor and evaluate the content created by rivals by scraping Medium. This allows them to stay up to date on industry advancements, better understand their rivals’ business plans, and adjust their own tactics accordingly.
Sentiment Analysis: Medium’s large user base makes it a perfect platform for analyzing sentiment, gauging public opinion, and eliciting strong feelings about particular subjects, goods, or companies. Data scientists may get a significant amount of textual data by scraping Medium. This allows them to employ specialized algorithms to measure public opinion. By offering insights into public opinion, this analytical method can be very helpful to organizations and brand strategists. It can help shape marketing strategies, brand campaigns, and product development.
Lead Generation: Medium serves as a venue for a wide variety of writers and opinion leaders from many sectors of the economy. Businesses can identify possible leads based on author profiles, interests, and areas of competence by utilizing web scraping tools. This focused strategy has the potential to grow clientele, produce worthwhile networking opportunities, and greatly improve lead generation efforts.
Data Mining for Machine Learning: Medium can be a valuable source of textual data for people in the Artificial Intelligence (AI) and Data Science fields. You can use Medium’s diversified content for machine learning, AI model training, and Natural Language Processing (NLP) applications by scraping it. The variety of subjects and writing styles found on Medium provides a top-notch corpus for testing and training algorithms, contributing to important developments in AI and machine learning methods.
Web Scraping Methods for Scraping Medium
Scraping Medium Post with Python
Web scraping tools such as BeautifulSoup and Scrapy have indeed become a staple in the realm of data acquisition and management. BeautifulSoup, a user-friendly Python package, wonderfully simplifies the process of parsing through HTML and XML documents to help for scraping Medium. On the other hand, Scrapy provides a robust and flexible solution for handling larger and more complex scraping assignments in Medium, such as different articles. With its ability to create powerful spider bots, Scrapy unfolds as an ideal tool for advanced data extraction from Medium.
For example, Python users who wish to scrape online material from Medium must use requests and web scraping packages such as Beautiful Soup. These libraries make it possible to extract HTML content from websites so that it can be used for data analysis. Here’s a condensed explanation of how to complete this task:
Please be aware that you should read and abide by the terms of service and robots.txt file on any website before attempting to scrape it. The terms of service of Medium may be broken by web scraping, which could lead to the blocking of your IP.
# Step 1: Import necessary libraries
from bs4 import BeautifulSoup
import requests
# Step 2: Make a request to the website
r = requests.get(‘http://medium.com/topic/popular’)
# Step 3: Parse the page content
soup = BeautifulSoup(r.text, ‘html.parser’)
# Step 4: Extract required information
articles = soup.find_all(‘div’, class_=’postArticle’)
for article in articles:
title = article.find(‘h3’).text if article.find(‘h3’) else ‘[No Title]’
print(‘Title: ‘, title)
This script sends a request to a Medium topic page, parses the HTML content of the page, finds all div tags with class ‘postArticle’, and then within each of these tags, finds the h3 tag (the tag that contains the title) and prints out the text.
Attention: You will need to make sure to use the proper class names as the website may update the classes and the structure of the website.
Scraping Medium Post without Coding
Adding to the variety, web scraping tools like Octoparse have risen as notable tools for providing more automated scraping options and steering towards a more user-centric approach. Powerful platforms make Medium scraping as seamless as possible, offering a beginner-friendly yet proficient environment for data extraction in Medium. With its advanced web scraping features, Octoparse shedding of the complexities is usually associated with data extraction.
There are several key factors to consider when it comes to choosing the right web scraping tool for scraping projects. For example, the size and complexity of the project definitely dictate the choice; if it’s a large scale and intricate task, a more comprehensive tool like Scrapy may be required. On the other hand, proficiency with coding is another consideration. While BeautifulSoup offers a gentle learning curve for beginners, tools like Octoparse are fantastic for those not comfortable with any coding. The tool’s usability, its capacity to handle dynamic websites, and the type of data you wish to extract are further factors to be contemplated upon. For websites like Medium, Octoparse with its robust built-in browser, intelligent data recognition can simplify the task. Now, let’s dive into how to use Octoparse scrape Medium data in detail.
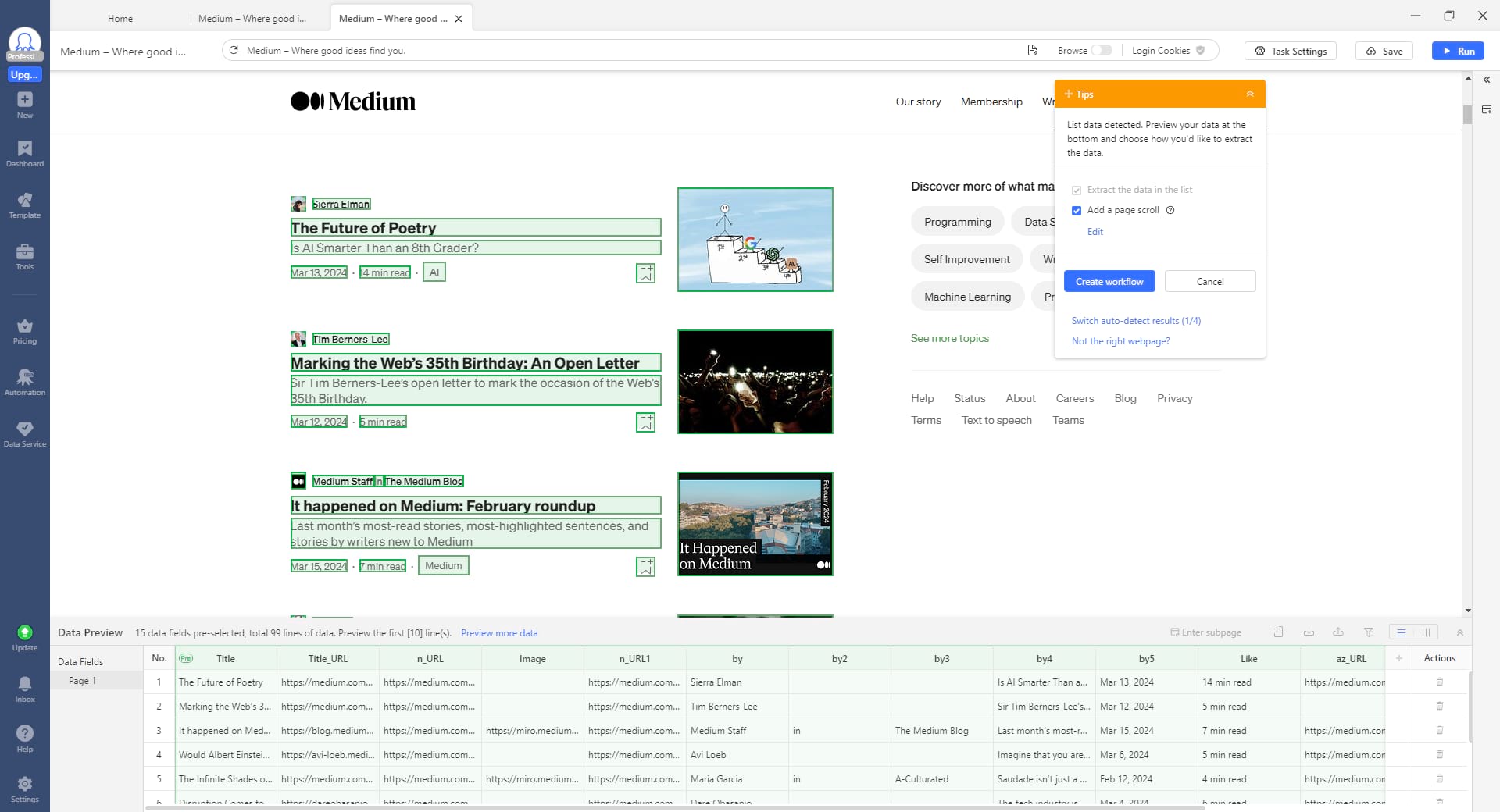
How to create a Medium scraper in Octoparse
Step 1: Create a new task to collect Medium data
Copy the Medium URL and paste it into the search bar on Octoparse. Then, click “Start” to generate a new scraping task.
Step 2: Create and modify the Medium scraper
The Medium page will be loaded into Octoparse’s built-in browser. Click “Auto-detect web page data” in the Tips panel after the page finishes loading. All extractable data will be colored with a green background on the page, so you can easily check if your desired data is selected or not. Then generate a workflow by clicking “Create workflow” once you’ve selected all the wanted data. The workflow will show up on the right-hand side. It contains every action of the operation. You are able to click on each one to check if it works as planned. You can also add new actions or remove any unwanted steps on this flow chart.
Step 3: Launch the Medium scraper
Once you’ve gone over everything, click the Run button to start the Medium scraper. You can run it locally on your device or remotely over the cloud depending on your needs. Finally, export the data to local files like Excel and CSV, or a database like Google Sheets for further use after the running is completed.
wrap up
Overall, Medium represents an invaluable resource for a wide array of users. Its diverse content, ranging from personal essays to professional insights, makes it an intriguing target for data scraping. By choosing a suitable web scraping tool, users can unlock Medium’s full potential in terms of market analysis, academic research, content creation, and business strategy formulation. Be it BeautifulSoup for simpler tasks, Scrapy for more complex scraping needs, or other web scraping software, these tools provide the key to harnessing the power of data in today’s digital information age.




