If you have ever tried to log in to a website, there’s a good chance that you have been asked to enter some characters that are not easy to read. The illegible characters are called CAPTCHA. They are a little bit annoying for users and often drive people who are using web scrapers crazy as they are hard to deal with by scraping bots.
In the following parts, you can learn the general knowledge of CAPTCHA and the easy methods on how to bypass CAPTCHA while web scraping.
What Is CAPTCHA
According to Wikipedia, CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is a type of challenge-response test used in computing to determine whether the user is human. This is a way to detect malicious robot behaviors, block the robot, and protect the website from harm.
It is commonly used across the internet, particularly when purchasing products online or logging into a website.
How Does CAPTCHA Work
CAPTCHA technology is based on the Turing Test. It is used to test whether a machine can think like humans. The goal of CAPTCHA is to ask questions or make challenges that computers are unable to deal with. It usually shows a distorted string of random characters or numbers. It works because a human looking at a distorted picture can read the words without any challenge, while a scraping tool doesn’t recognize them easily.
Even the most sophisticated automated system, which has been programmed to scan a picture of printed text and read the words, would still find it difficult to identify the words when they are too much distorted.
Common Types of CAPTCHA
CAPTCHA comes in several sizes and different types. The most common types of CAPTCHA are:
- Text-based Captcha
- Image-based Captcha
- Audio-based Captcha
- ReCaptcha vs. Captcha
Text-based CAPTCHA
A text-based CAPTCHA test is made up of two parts: a randomly generated sequence of letters and/or numbers that appear as a distorted image, and a text box for input. To pass the test and prove your human identity, simply type the characters you see in the image into the text box.
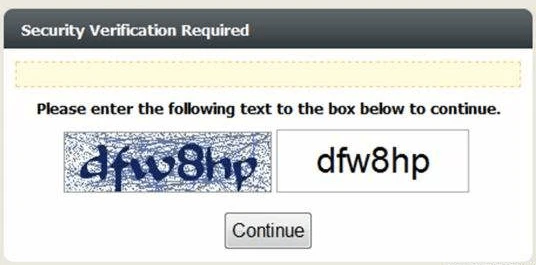
Simply showing the characters are not that difficult for bots. To increase the difficulty, there is mathematical CAPTCHA, which involves a basic math problem with easy-to-read numbers, and 3D CAPTCHA, which displays the characters with a 3D effect.
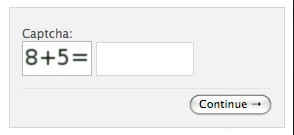

Image-based CAPTCHA
Image-based CAPTCHA usually provides users with images of objects, animals, people, or landscapes, instead of distorted text, to distinguish a human from a computer program. Users are required to select the correct images that they are asked to identify or drag a block into an image to make it complete.

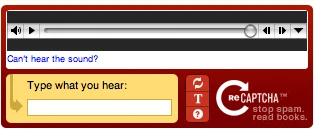
Audio-based CAPTCHA
Audio-based CAPTCHA utilizes random words or numbers drawn from recordings, combines them, and even adds some noise to them. The users are required to enter the words or numbers in the recording. Sound CAPTCHAs are harder to deal with compared with content and picture CAPTCHAs as it is not easy to let a scraping bot learn to listen.
ReCaptcha vs. hCaptcha
Compared to Captcha, Google’s reCaptcha now is more widely used among websites. There are fair reasons:
- For developers, it is easier to set up and maintain
- The test is more friendly for users to solve (sometimes those squiggly letters can be really tricky)
- Free service is available and Google is taking good care of it
However, even reCaptcha with an easy question can interrupt the smooth browsing journey and annoy the user. So there comes invisible reCaptcha.
“Google’s Invisible reCAPTCHA service, which is able to differentiate humans from bots without additional input from the website user. reCAPTCHA uses an advanced risk analysis engine and adaptive CAPTCHAs to keep automated software from engaging in abusive activities on your site. It does this while letting your valid users pass through with ease.”
——Quoted from InterGen.com

You may have heard about hCaptcha and wonder what is the difference between hCaptcha and reCaptcha.
In fact, reCaptcha is offered by Google, and with the service set up on your site, every time when your users solve a captcha, the user data is fed back to Google. Google may use this data to improve its services, for example, teach the machine to categorize photographs more intelligently. While it can be sensitive as well in regard to personal privacy.
Hcaptcha is provided by Intuitive Machine which is far from a data tycoon and claims to protect user privacy.
Why Do Websites Apply CAPTCHA
Nowadays, computing has become pervasive, and computerized tasks and services are commonplace, so increased levels of security have been more important. The development of CAPTCHA for computers is to ensure that they are dealing with humans in situations where human interaction is essential to security, for example, logging into a website or paying on the Internet.
CAPTCHA also blocks spammers and bots that try to automatically harvest online data, and try automatically signing up for or make use of websites, blogs, or forums. It protects websites from being overrun by spam, fraudulent registrations, and other illegal behaviors.
How to Deal With CAPTCHA for Web Scraping
CAPTCHA can easily break down the crawlers you set up once it shows in the process of extraction, so dealing with it is quite essential for web scraping. The best way to deal with a CAPTCHA is to try your best to avoid encountering it in the face :).
That means we try to avoid triggering the Captcha in the first place:
- Slow down the scraping to make your behaviors less robot-like
- Make use of proxy servers to minimize IP tracing
- Be careful of honeypot traps
When you face CAPTCHA head-on and do not come back, there are ways to solve it.
If you use Octoparse, the best web scraping tool, which is easy to use and without any coding needs. Here are the simple steps on how to solve CAPTCHAs with it.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
1. Resolve Captcha manually under browse mode in local extraction
- Switch on Browse mode from the top right corner – resolve the Captcha just like you would do in a normal browser – switch off Browse mode to continue to build your task
2. Save cookies to avoid encountering Captcha
After solving the captcha in Browse mode, you can also save the current page cookies to reduce the chance of them appearing again.
- Click on Go to Web Page
- Go to Options in the Settings section and tick Use cookie
3. Resolve Captcha manually for local extraction
If the captcha shows right after the local run starts, you can try this workaround.
- Go to the browser, click Pause directly
- Manually solve the captcha in the extraction window
- Go on the run by clicking the Resume button in the top left corner of the extraction window
You can read more details if you still have questions about solving CAPTCHA with Octoparse while scraping.
For people who code their own scrapers, there are many CAPTCHA solvers that can be integrated.
- Death by CAPTCHA: this service allows users to connect the service via API to realize solving CAPTCHA automatically during the scraping process.
- Bypass CAPTCHA: this CAPTCHA-solving tool can deal with normal text CAPTCHA and even reCAPTCHA.
- 2CAPTCHA: 2Captcha is a wonderful service provider to help you solve the problem.
CAPTCHA can be a painful headache for web scraping. But don’t worry. With every generation of CAPTCHA, there is every generation of bots. CAPTCHA has become defeatable with the rise of scraping tools and CAPTCHA solvers. You can enjoy web scraping unimpededly with the help of these tools.